Was hat meine Königspython mit Big Data und Analytics zu tun?
November 18, 2018
Aus dem Unterricht des CAS Disruptive Technologies mit Dr. Simon Hefti berichtet Mischa Kemmer. Für eine Einführung und verschiedenen Case Studies von Big Data und Analytics wird auf den Blog von Mensur Kutleshi verwiesen.
Wer sich heute im Unternehmen mit Big Data und Data Analytics auseinandersetzt, sollte die folgenden Stolpersteine vermeiden:
Big Data ist ein Business Enabler und somit muss am Anfang eines solchen Projekts oder einer Initiative immer der Use oder Business Case mit konkreten Fragen untermauert werden:
Basierend auf dem Integration Maturity Model kann ein zentraler Ansatz gewählt und somit auch dem Thema Data Governance Rechnung getragen werden. Wichtig ist hier der Stakeholder Einbezug! Die Initiative soll den Fokus auf den Kunden legen, was z.B. die Konkurrenz macht ist zweitrangig. 
Anforderungen an die Datenqualität, Datenautorisierung und Benutzerverwaltung, das Datenmodell und die Identifikation und Priorisierung der benötigenden Erweiterungen und Veränderungen, jedoch auch (je länger je mehr!) die gesetzlichen und regulatorischen Anforderungen, sind Entscheidungsfaktoren für den Erfolg des Vorhabens! Ein Data Governance Board sollte hier in der Verantwortung stehen, um die Kontrolle über das Thema zu haben. Die Informationen (Data) sollten die tiefst mögliche Granularität aufweisen, vernetzt sein und entlang der 6C Regel aufbereitet werden:
Wie oben bereits erwähnt, muss für jeden Anwendungsfall geklärt werden, ob dieser Sinn macht (Build the case). Nach dieser Klärung kann dieser in den Geschäftsprozess eingepflegt und integriert werden (Implement). Wichtig sind in dieser Phase Milestones zu haben, damit greifbare und handfeste Resultate erzielt werden können. Sprints von 6 – 8 Wochen sind hier sinnvoll.
In einem letzten Schritt soll weiterentwickelt werden, d.h. das Datenvolumen nimmt zu oder wir können weitere Anwendungsfälle bearbeiten (Extend).
Es ist wichtig zu verstehen, dass Strategie und Implementation zeitlich den kleineren Teil darstellen, Themen in der Transition wie Data Governance (Committee, Data Standards), Kultur (Kommunikationsplan) und Organisation (Job Description, zentrales oder dezentrales Team) hingegen viel zeitintensiver sind.
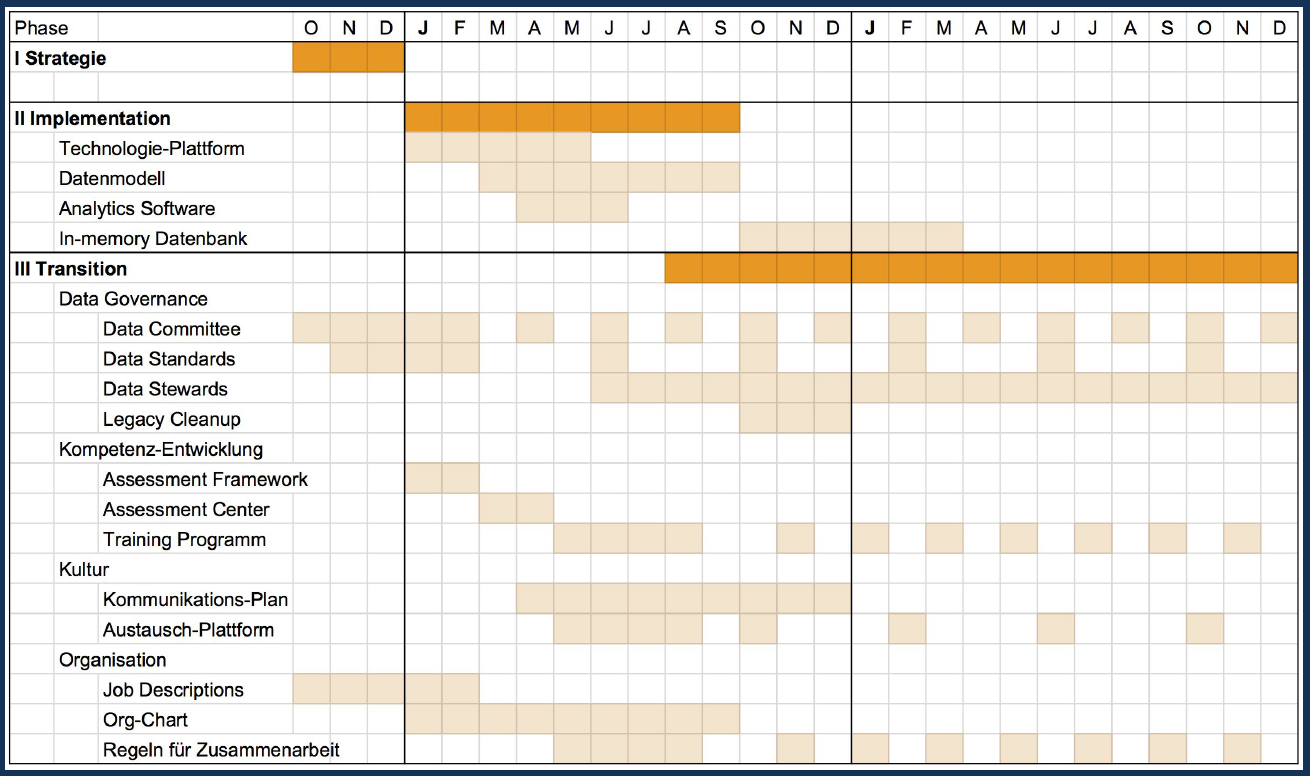
Die Technologie kommt am Schluss und sollte nach Möglichkeit mit der Infrastruktur des Unternehmens kompatibel sein, damit in den Bereichen wie z.B. Storage oder bei der Verwendung von Reporting Anwendungen, Synergien genutzt werden können.
Hier wäre nun der Zusammenhang zum Titelbild angebracht – meine beiden bald 38-jährigen (Königs) Pythons als Namensgeber für die viel verwendete Programmiersprache “python”.
Die praktische Bearbeitung unserer Big Data erfolgt mittels Algorithmen, sprich eine Vorgehensweise, um ein Problem zu lösen. Anhand dieses Lösungsplans werden in Einzelschritten Eingabedaten in Ausgabedaten umgewandelt.
Oft ist die Suche nach dem richtigen Algorithmus für die entsprechende Aufgabe nicht offensichtlich. Nachfolgend die grundlegenden Bereiche des maschinellen Lernens und eine Übersicht, welche Art von Algorithmen in einer bestimmten Situation verwendet werden können.
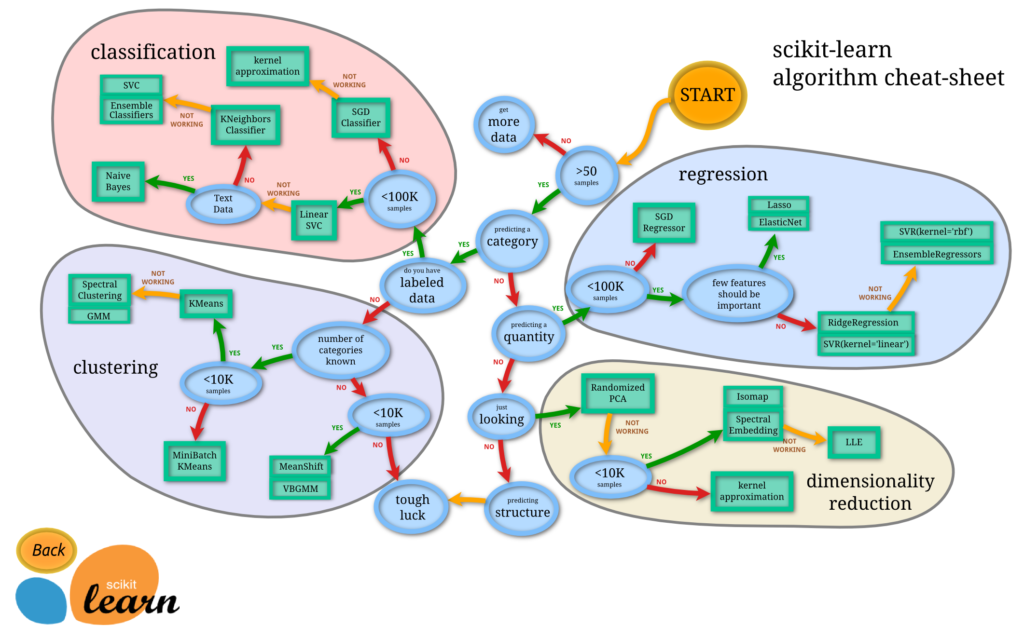
Im Bereich der Regression oder Classifikation haben wir den Decision Tree Algorithmus kennengelernt.
Das Verfahren wird beispielsweise dazu verwendet, um die Kundenloyalität vorherzusagen, also das Risiko, ob ein Kunden zur Konkurrenz abwandert.
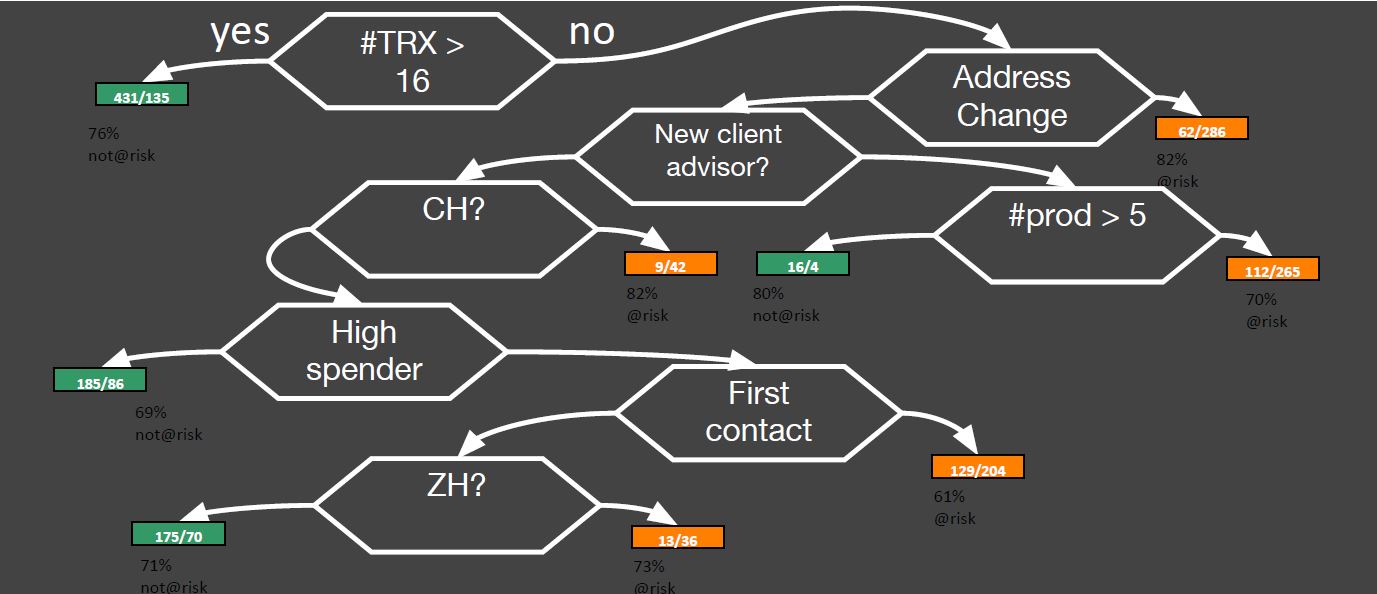
Wichtige Schritte beim Erstellen eines Decision Tree: mittels Trainingsdaten erstelle ich zuerst ein Neuronales Netzwerk, damit ich die Daten labeln kann (Callibration).
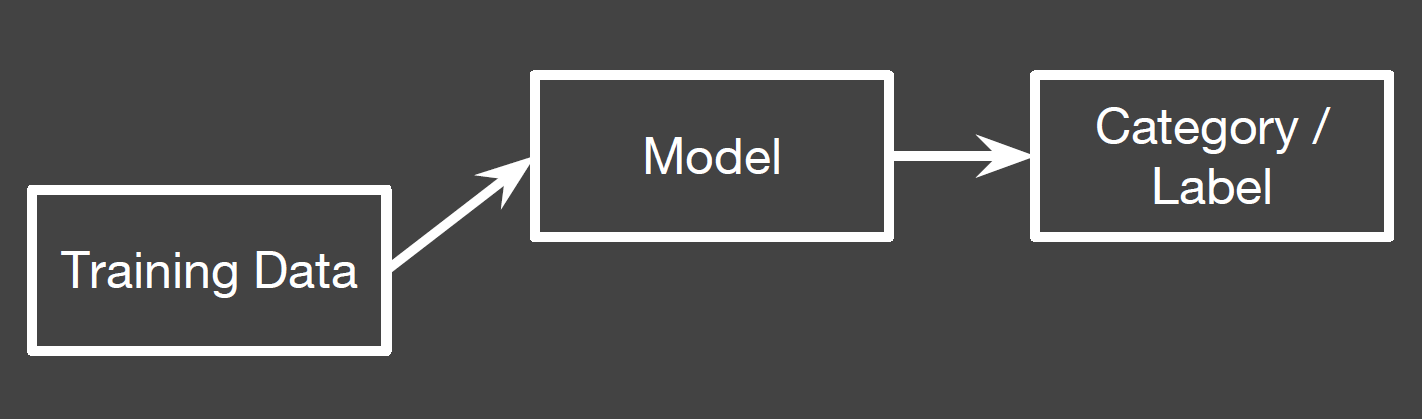
In einem weiteren Schritt wird das Verfahren auf die realen Daten angewendet, damit auch diese Daten gelabelt werden (apply model to real data). Im letzten Schritt muss eine stetige Überprüfung der Resultate stattfinden (Monitoring).

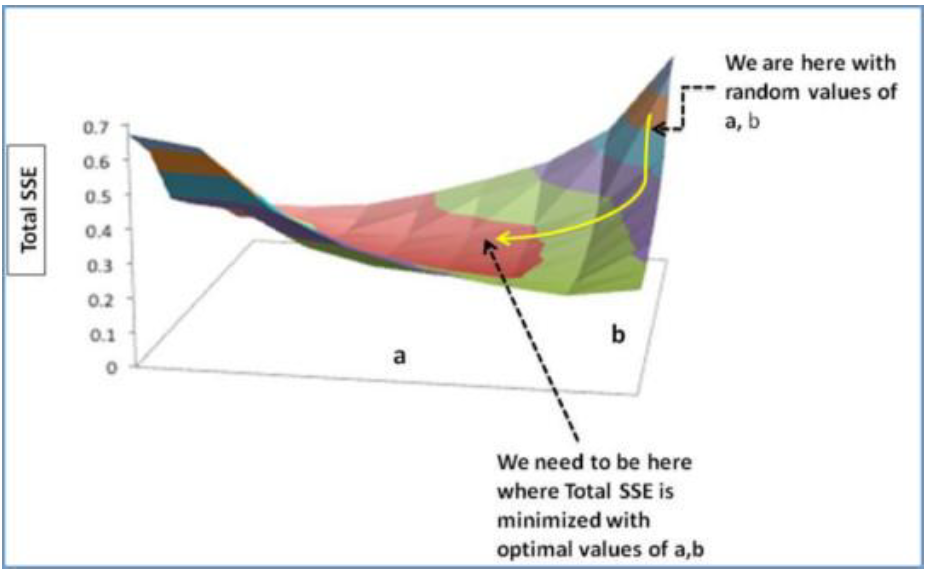
Der Gradient Descent Algorithmus ist einer der beliebtesten Optimierungsalgorithmen, um optimale Parameter zu finden – vergleichbar mit einem Skifahrer, der die optimale Streckenführung fährt.
Weiter haben wir im Bereich Clustering Boosting kennengelernt. Die Idee des Boosting besteht darin, schwache Lernende sequentiell zu trainieren, wobei jeder versucht, seinen Vorgänger zu korrigieren.
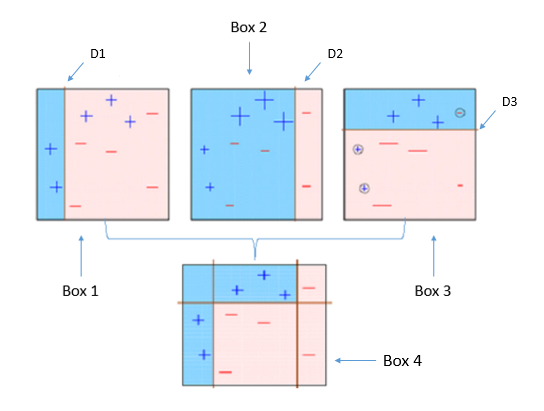
(D1) wird gebildet, und trennt den (+) blauen Bereich von dem (-) roten Bereich. D1 hat drei falsch klassifizierte (+) im roten Bereich. Die falsch eingestufte (+) wird nun höher gewichtet und weitergeleitet. Das Modell fährt weiter so fort und passt den Fehler an, bis wir eine saubere Einteilung von rot und blau in (-) und (+) haben. Dies kann also verwendet werden, wo eine automatische Klassifikation in zwei Klassen benötigt wird, z.B. um Bilder von Gesichtern in „bekannt“ und „unbekannt“ zu unterteilen.
Ein weiterer Algorithmus ist K-Means. Eine Menge von Datenelementen wird gruppiert, wie z.B. alle traurigen Songs oder alle fröhlichen Songs der Hitparade.
Als Abschluss haben wir das Thema Perceptron diskutiert. Der Hauptbestandteil eines jeden künstlichen neuralen Netzwerks ist das künstliche Neuron. Das künstliche Neuron verfügt über eine Reihe von Eingangskanälen, eine Verarbeitungsstufe und einen Ausgang, der sich auf mehrere andere künstliche Neuronen verteilen kann.
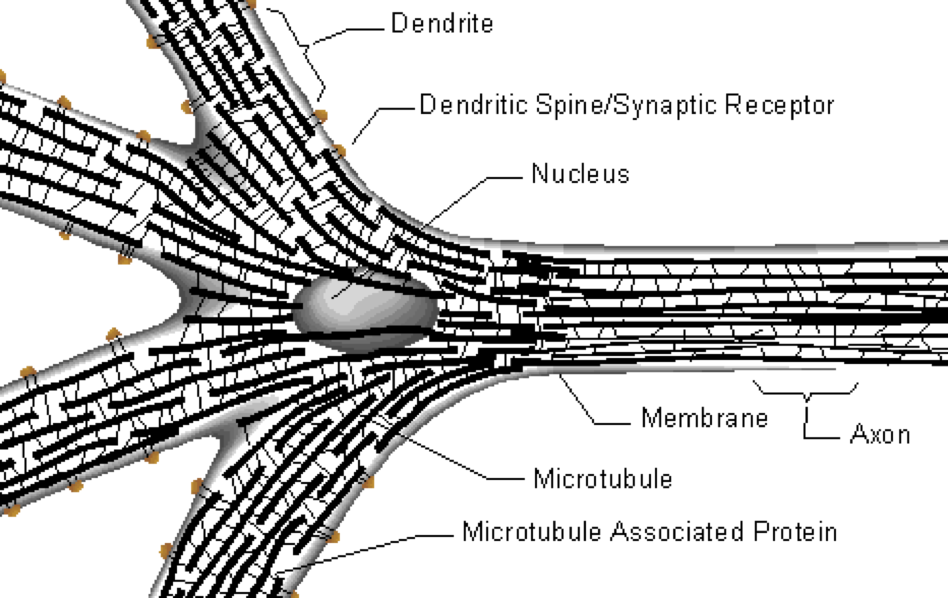
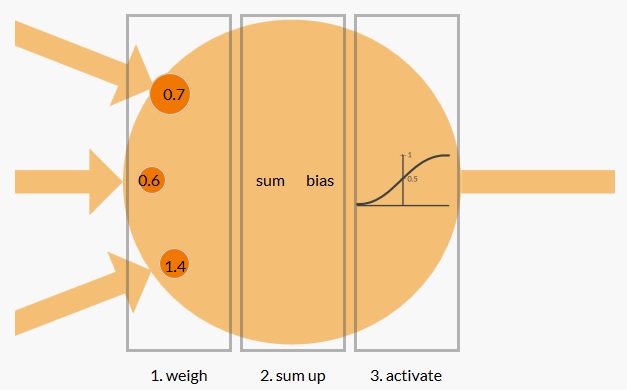
In einem ersten Schritt wird pro Kanal ein Wert vergeben. Im zweiten Schritt werden die Werte aufsummiert. In diesem Schritt wird auch ein Offset zur Summe addiert. Dieser Offset wird als Bias bezeichnet und während der Lernphase korrigiert. Nun wird es spannend – nach jeder Lerniteration werden die Werte und der Bias schrittweise verschoben, so dass das nächste Ergebnis dem gewünschten Ergebnis etwas näher kommt. Auf diese Weise bewegt sich das neuronale Netzwerk allmählich in einen Zustand, in dem die gewünschten Muster “gelernt” werden. Schliesslich wird das Ergebnis der Berechnung des Neurons in ein Ausgangssignal umgewandelt.
Bildmaterial und Grafiken stammen aus dem Foliensatz von Dr. Simon Hefti.
Unser Newsletter liefert dir brandaktuelle News, Insights aus unseren Studiengängen, inspirierende Tech- & Business-Events und spannende Job- und Projektausschreibungen, die die digitale Welt bewegen.