Machine Learning: Neu! Jetzt auch in Ihrer Nähe
März 10, 2020
Machine Learning konnte in den letzten 10 Jahren eine markante Zunahme medialer Präsenz verzeichnen. Dabei sind die zugrunde liegenden Theorien nicht neu. Sie existieren seit ca. 30 Jahren.
Warum also dieser plötzliche Hype?
Als Tim diese Frage in den Raum stellt, warten wir gespannt auf die Antwort.
Das liegt an der Digitalisierung vieler Geschäftsprozesse und den beachtlichen Mengen von Daten, die daraus gewonnen worden sind, erklärt uns Tim. Zusätzlich können wir heutzutage auf ausreichend Rechenleistung zurückgreifen um mit diesen Daten arbeiten zu können.
Doch was ist Machine Learning? Ein belesener Roboter, der anderen Roboter die Welt erklären kann?

Reading Robot
Tim beschreibt uns Machine Learning möglichst einfach: Es handelt sich um Algorithmen, die sich selber verbessern können. Je öfter sie zum Einsatz kommen, desto exakter werden ihre Ergebnisse. Frank Lorand betrachtet in seinem Blog verschiedene Algorithmen etwas genauer.
Beim überwachten Lernen erhält der Algorithmus vom Menschen als Lehrer, ein Gesamtpaket an Informationen zur Datenanalyse. Die Daten sind uns demnach bekannt und sie sind klar beschrieben. Der Algorithmus kennt dadurch den Zusammenhang zwischen verschiedener Attribute und Eigenschaften der Daten. Auch zu erwartende Ergebnisse der Datenanalyse hat der Mensch dem Algorithmus mitgegeben. Somit kann der Algorithmus seine eigenen Ergebnisse mit den erwarteten abgleichen und daraus lernen.
Beim unüberwachten Lernen kennt der Algorithmus keinen Zusammenhang in den Daten. Da der Mensch nicht als Lehrer fungiert, sind ihm auch die erwarteten Ergebnisse gänzlich unbekannt. Der Algorithmus versucht nun ganz alleine, in einem explorativen Modus, die Daten in einer bestimmten Art und Weise zu gruppieren oder Muster bzw. Anomalien zu erkennen.
Beim bestärkenden Lernen lernt der Algorithmus mittels Belohnungssystem mit seinem Umfeld zu interagieren. Als Ausgangspunkt verfügt er über eine oder mehrere Strategien (policies), welche bestimmte Aktionen im Umgang mit seinem Umfeld beinhalten. Der Algorithmus erzielt bei korrekten Aktionen Punkte. Somit versucht er möglichst vieler Punkte zu erreichen und optimiert dabei laufend seine Strategie.
Es gibt viele Methoden wie Daten analysiert werden können. Einige Beispiele sind Random Forrest, K-Nearest Neighbors und Logistische Regression. Tim erklärt uns was diese Methoden und ihre Algorithmen mit den Daten anstellen:
Daten werden bspw. klassifiziert. Das bedeutet, dass Daten in klare Gruppen eingeteilt werden können. Dafür müssen die Daten, deren Eigenschaften und Attribute beschrieben und bekannt sein. Sinnvolle Gruppen werden bereits vor der Datenanalyse gebildet. Neu hinzukommende Daten werden nun diesen bestehenden Gruppen zugeordnet (klassifiziert).
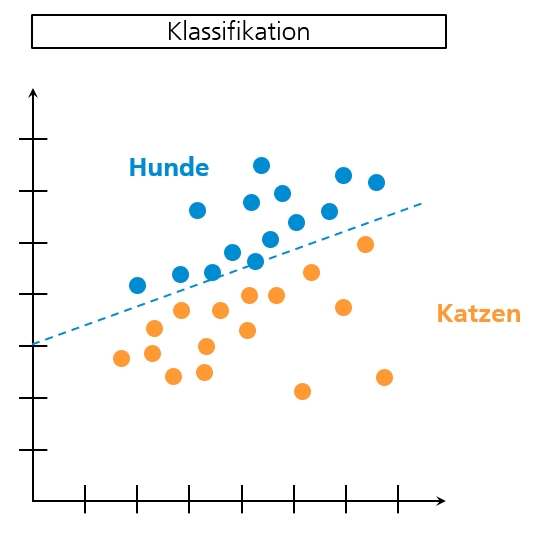
Beispiel: Ein neues Bild wird in die Gruppe Hunde- oder Katzenbilder eingeordnet
Daten werden einer Regression unterzogen. Das bedeutet, dass mit bekannten Daten Prognosen oder Trendanalysen erstellt werden. Damit dies möglich wird, müssen ebenfalls Daten, deren Eigenschaften und Attribute beschrieben und bekannt sein.
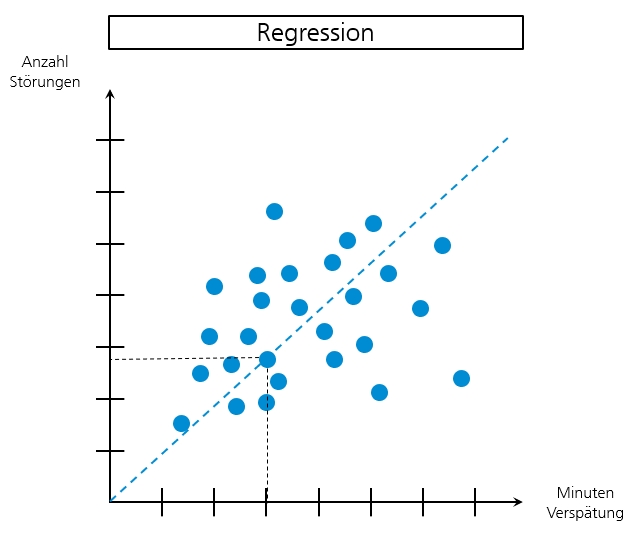
Beispiel: Wie viele Minuten Verspätung hat die S-Bahn aufgrund von Stellwerkstörungen
Daten werden aufgrund ähnlicher Eigenschaften in Cluster eingeteilt. Anders als bei der oben beschriebenen Klassifizierung, existieren hierfür keine vordefinierten Gruppen. Attribute und Eigenschaften der Daten sind nicht beschrieben und dem Algorithmus unbekannt. Deshalb bildet der Algorithmus diese Cluster nach eigenem Ermessen.
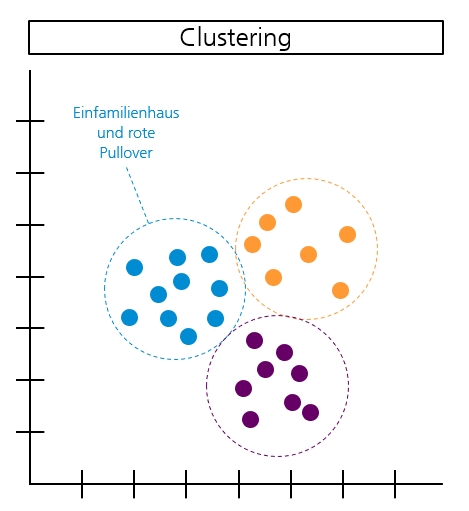
Beispiel: Menschen, die in einem Einfamilienhaus leben und rote Pullover tragen
In den Daten werden Muster und Anomalien erkannt. Das bedeutet, vorhandene Daten werden nach Gemeinsamkeiten und Abweichungen analysiert. Auch in diesem Beispiel ist der Zusammenhang zwischen Attributen und Eigenschaften der Daten nicht beschrieben. Deswegen sucht der Algorithmus selbstständig nach Mustern und Anomalien.
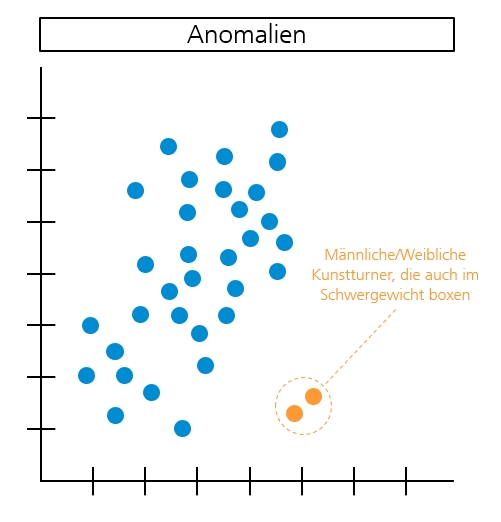
Beispiel einer Anomalie: Aufgrund offensichtlich inkonsistenter Daten, gibt es männliche/weibliche Kunstturner, die gleichzeitig in der Schwergewichtsklasse boxen
Wie finde ich heraus, welche Methode für meine Daten am besten geeignet ist?
Dafür müssen wir unsere Daten in ein Training-Set und ein Testing-Set unterteilen. Jede Methode wird nun einzeln mit dem Training-Set trainiert und mit dem Testing-Set getestet. Tim erklärt uns, dass die Ergebnisse, wie jede Methode im Testing-Set abgeschnitten hat, am besten in einer Confusion Matrix abgebildet werden.
Die Reihen in der unten abgebildeten Confusion Matrix zeigen auf, wie die Methode abgeschnitten hat (Achse: Algorithmus).
Die Spalten in der unten abgebildeten Confusion Matrix geben die uns bekannte Realität wieder (Achse: Uns bekannte Realität).
Die grünen Felder in der unten abgebildeten Confusion Matrix, entsprechen korrekten Treffern.
Die gelben Felder in der unten abgebildeten Confusion Matrix, entsprechen falschen Treffern.
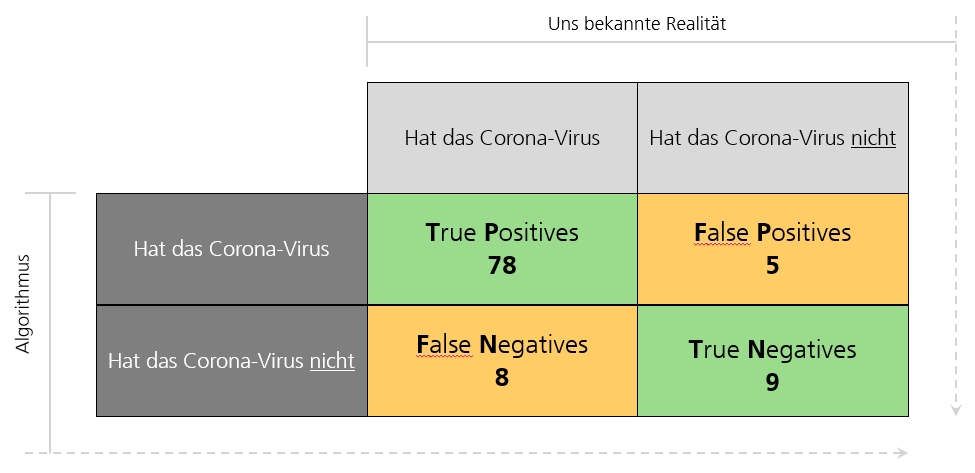
Aus aktuellem Anlass verwende ich ein Beispiel mit dem Corona Virus. Das Testing-Set dieses Beispiels beinhaltet 100 Menschen. Methode 1: Logistische Regression hat 78 Menschen korrekt als infizierte mit dem Corona Virus erkannt (True Positives). 9 Menschen hat Methode 1 korrekt als nicht infizierte Menschen erkannt (True Negatives). Allerdings hat Methode 1 auch 8 Menschen irrtümlich als gesund eingestuft, obwohl sie den Virus in sich tragen (False Negatives). Methode 1 hat ausserdem 5 Menschen irrtümlich als infiziert eingestuft obwohl sie gesund sind (False Positives).
Das gleiche Testing-Set mit denselben 100 Menschen würde nun auch mit Methode 2: Random Forest durchgeführt werden. Anschliessend können wir die Ergebnisse beider Methoden vergleichen und die für uns geeignetere auswählen.
Zum Abschluss dieses spannenden Morgens gibt uns Tim noch einen Tipp mit auf den Weg. Bei der Auswahl der Methode anhand der Confusion Matrix, sollen wir stets den Anwendungsfall berücksichtigen. Je nachdem kann es durchaus besser sein, diejenige Methode zu wählen, welche am wenigsten False Negatives aufweist.
Bleibe auf dem Laufenden über die neuesten Entwicklungen der digitalen Welt und informiere dich über aktuelle Neuigkeiten zu Studiengängen und Projekten.