KI Projekte – Realität oder Fiktion
Juli 5, 2019
Was muss beachtet werden, um ein erfolgreiches AI Projekt umzusetzen? Was sind die Erfolgskriterien? Was kann alles schieflaufen? Und wie komme ich aus einer Schieflage während dem Projekt wieder heraus? Wie schafft man Akzeptanz für ein AI Projekt?
Dank diverser Erfahrungen in erfolgreich umgesetzten AI Projekten konnten viele Cases aufgezeigt und Fragen rund um das Thema AI Projekte, durch Simon Hefti beantwortet werden.
Es gilt zuerst einmal einen Business-Case zu identifizieren, welcher sich für die Technologien der Künstlichen Intelligenz eignet.
Einen Business-Case zu identifizieren, welcher einen Mehrwert bringt und sich mit den Technologien der Künstlichen Intelligenz befasst, ist nicht einfach. Somit stellt sich als erstes einmal die Frage, ob ein KI Projekt überhaupt nötig ist?
Das Besondere an KI Projekten ist aber, dass erfolgreiche Projekte und Anwendungen enorm skalieren und dem Unternehmen einen grossen Wettbewerbsvorteil bringen können.
Um beurteilen zu können, ob es sich um ein sinnvolles KI Projekt handelt, muss vorerst die Entscheidungs-Psychologie hinter dem Business Case und dessenNutzen vor Augen gesetz werden. Zum Beispiel mit dem Modell “The essence of Winning and Losing” von John, R. Boyd.
Die richtige Entscheidung (decide), im richtigen Moment zu treffen,und dazu auch noch im angebrachten Augenblick zu handlen (act) spielt dabei eine ausschlaggebende Rolle . Je nach Prozess, welcher durchläuft wird, können dabei Millisekunden, Stunden, Tage oder Wochen vergehen.
Beispiel:
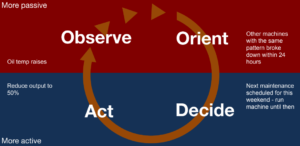
Die Öl Temperatur meiner Maschine steigt
Andere Maschinen mit den gleichen Anzeigen waren 24 Stunden später kaputt
Nächste Wartung der Maschine wird für das Wochenende geplant
Maschinen Output bis am Wochenende um 50% reduzieren
Der Zeitpunkt der Entscheidung zwischen Decide und Act ist enorm wichtig, da wir uns ansonsten im Entscheidungsprozess zurück auf Observe werfen und den Zyklus (Observe, Orient, Decide, Act) nochmals durchlaufen müssten.
Weitere Beispiele:

KI kann in unserem Fall helfen, vorausschauend die richtige Entscheidung, im richtigen Moment (Maschine am Weekend warten), anhand der Erfahrungswerte (andere Maschinen mit der gleichen Anzeigen waren 24 Stunden später kaputt) zu treffen und somit einen Mehrwert (die Maschinen gehen weniger kaputt) für das Unternehmen zu schaffen.
Basis für die richtige Prozessierung / Entscheidung sind somit die Daten. Es stellt sich als Folge dessen die Frage: Können Daten als Strategic Asset bezeichnet werden, welche meine Unternehmensbilanz positiv beeinflussen? Daten alleine sind noch kein Stratigic Asset. Jedoch sind Daten, welche sich in Informationen und dadurch in Wissen umwandeln lassen, sehr wertvoll. Dieses Wissen kann für ein Unternehmen ein Wettbewerbsvorteil mit sich bringen.
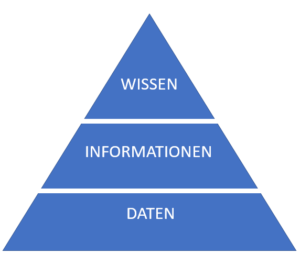
Beispiel der Maslof-Pyramide für Daten
Wann wird der Kunde den Vertrag mit unserer Firma künden?
Eine Kündigungsberechnung zu erstellen und somit eine Voraussage für den Zeitpunkt der Kündigung zu machen, ist nicht ganz einfach. Um dies zu ermöglichen, wurde ein Predictive Model (z.B Decision Trees) genutzt. Die Daten für das Model konnten aus dem CRM System (Sales: Wie lange hat der Kunde nichts mehr bestellt oder das letzet Mal mit unserem Sales Team gesprochen? Wievielmal hat er mit unserem Tech-Support zu tun gehabt?) entnommen werden. Ähnliche Kundensegmente (balanced twin design) wurden erstellt und berücksichtigt, um diese «Client at Risk» besser zu erkennen. Die «Client at Risk» wurden direkt im CRM gekennzeichnet. Mit Hilfe einer Confusion Matrix (https://www.youtube.com/watch?v=Kdsp6soqA7o) kann die performance des Klassifikationsmodell berechnet werden. In diesem Fall war der Cost für ein False nur der zusätzliche Aufwand für den Sales mit den «Client at Risk».

Wo sollen die 1000 Offerten hin, welche die Firma elektronisch erhält? Wie kommt die richtige Offerte zur richtigen Abteilung?
Eine Spracherkennungsanwendung (NLP – Natural Language Processing) kann die Offerte, dank Keywords lesen und somit der korrekten Abteilung zuteilen. Falls die Triage falsch läuft, wird wieder manuell (von einem Mitarbeiter) weitergeleitet.
Wie kann die Liegenschaftsverwaltung sicherstellen, dass alle Wohnungen immer vermietet sind?
Aus Vertragsdaten und den Attributen (familiäre Situation), der wirtschaftlichen Situation, der Entwicklungen in der Nachbarschaft und von ähnlichen Gebäuden wurde ein Model erstellt, welches der Liegenschaftsverwaltung ermöglicht, die Vermietung ihrer Liegenschaften zu optimieren. Da in diesem Model sehr viele externe Faktoren mitspielen (Wirtschaftslage, Nachbarschaftsentwicklung…) ist die Genauigkeit mit 76% eher tiefer, als bei anderen KI Modellen. Doch ist der Vergleich mit den Kosten für eine falsche Voraussage immer noch interessant.
Wie kann eine Krankheit aus Blutwerten vorausgesagt werden?
Der Datensatz aus 24 Messwerten im Blut wird mit anderen Personen verglichen. Hier ist die Genauigkeit natürlich essentiell. Der Cost of false negative: Wird die Krankheit nicht erkannt, verspätet sich die Behandlung. Der Cost of false positive ist weniger schlimm. beansprucht aber die Zeit des Arztes. Somit wird dieses Projekt nicht die Entscheidung des Arztes ersetzen, sondern nur die Einschätzung des Arztes (bis zu 97% Genauigkeit) unterstützen.
Können sich die Steuerungssysteme der Windturbine frühzeitig der Windrichtung anpassen, um somit mehr Strom zu produzieren?
Aus Wetterinformationen und durch die Optimierung der Steuerungssysteme kann mit Hilfe von KI 10-15% mehr Energie gewonnen werden.
Wie kann man sicherstellen, dass der Kunde eine gute Erfahrung beim Testen des Hörgeräts macht?
Die erste Erfahrung mit dem Hörgerät entscheidet, ob es weiterhin genützt wird. Dank Klangbilder bei ähnlichen Benutzern können die richtigen Anpassungen schon bei der ersten Einstellung vorgenommen werden und somit negative Erfahrungen minimiert werden.
Wie kann ich auf dem App Store ein besseres APP Rating haben als meine Konkurrenz (Uber)?
In der user journey kann verfolgt werden, wann/wer ein ein gutes oder schlechtes Rating im App Store in der Vergangenheit abgegeben hat und somit die Frage: «Wie zufrieden waren Sie mit der Fahrt» zur Rating App steuern. Beispiel: 5 Sterne von 5 = Möchten Sie die App bewerten? Oder 2 Sterne von 5 = Nicht für das Rating der APP geeignet.
Weitere Beispiele von erfolgreichen KI Projekten zeigten, wie die Abschlusswahrscheinlichkeit von Lebensversicherungen gesteigert werden kann oder eine Vorhersage zu den Besucherzahlen für ein Event besser eingeschätzt werden kann.
Wie bei allen IT Projekten, kann auch bei AI Projekten Einiges schieflaufen. Was kann ich nun aber machen, um sicherzustellen, dass ein KI Projekt nicht in die Schieflage gerät? Bei vielen Unternehmen scheitern KI Projekte an der Basis, da die Daten nicht digitalisiert worden sind.
Die Konsequenzen für ein Scheitern des KI Projektes können je nach Anwendung sehr gravierend sein. KI Waffen, selbstfahrende Autos (Unfallsituation) oder ein nicht erkanntes Krankheitsbild können sogar tödliche Folgen haben.
Die Auswahl der Trainingsdaten bestimmt, wie die KI funktioniert. Es müssen somit unbedingt eine Sensitivitätsanalyse und eine Überwachung stattfinden.
Das Ziel von Data poisoning ist es, in der Trainingsphase falsche Voraussagen hervorzurufen. Dazu werden die Datenquellen manipuliert. Der Chatbot Tay von Microsoft war ein interessantes Beispiel dafür.
Zusätzliche Informationen eingeben (z.B falsche/fake Pixel) für die Bilderkennung oder die Teststrassen für ein selbstfahrendes Auto mit Markierungen am Boden manipulieren.
Die Identität von jemand anderem vorzutäuschen, zum Beispiel durch einen Fingerabdruck auf ein Glas.
Flugranfragen (erhöhen?) manipulieren, um die Nachfrage danach zu steigern.
Mit gezielten Anfragen ein Bild wiederherstellen, um die Identität von jemandem herauszufinden.
Machine Learning (ML) findet Muster in Daten. Mit Bias meint man, dass falsche Muster gefunden werden:
Google Flu Trends: https://www.sueddeutsche.de/wissen/big-data-google-versagt-bei-grippe-vorhersagen-1.1912226
Amazon Bewerbungsverfahren: https://www.heise.de/newsticker/meldung/Amazon-KI-zur-Bewerbungspruefung-benachteiligte-Frauen-4189356.html
Google Bilderkennung: https://www.spiegel.de/netzwelt/web/google-fotos-bezeichnet-schwarze-als-gorillas-a-1041693.html
Gibt das Projekt ein betriebswirtschaftlicher Mehrwert und gibt es einen konkreten Business Case? In den ersten Wochen muss abschätzbar sein, ob es einen POC (Proof of Concept) gibt.
Sind die 6 Cs für unsere Daten gewährleistet?
Was ist mit der Technologie und Architektur?

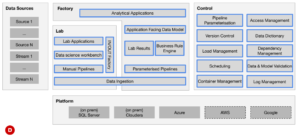
Wie steht es um die Genauigkeit des Modells und wieviel Toleranz vermag es bei einer negativen Entscheidung? False Positves, False Negatives, Known Cases, Edge Cases.
Wie sensibel ist das Model auf zusätzliche Daten (Noise)?
Wer trägt die Verantwortung für das Model?
«Wenn ein Foto fälschlicherweise als Gorilla klassifiziert wird, dann ist das ein Engineering-Fehler, der analog zu behandeln ist, wie wenn die Brücke einstürzt: der Engineer hat unsorgfältig gearbeitet und wird zur Verantwortung gezogen.» S. Hefti
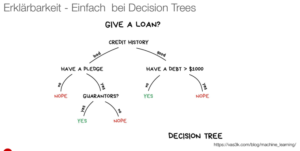
Ist die Erklärbarkeit des Modells sichergestellt und die Reproduzierbarkeit sichergestellt?
Was für Rollen brauchen wir für das Projekt um einen Proof of Concept zu gewährleisten:
«Machine Learning and Artificial Intelligence systems are stupid. While they are useful tools in the hand of man, blindly following machine recommendations will lead you “into the river”.» S. Hefti
Unser Newsletter liefert dir brandaktuelle News, Insights aus unseren Studiengängen, inspirierende Tech- & Business-Events und spannende Job- und Projektausschreibungen, die die digitale Welt bewegen.