Ich weiss, was du nächsten Sommer tun wirst
Januar 4, 2016
Aus dem Unterricht des CAS Mobile Business mit Dr. Marcel Blattner berichtet Louis Gil:
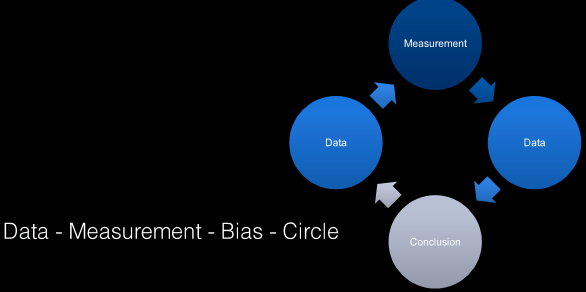
Bei Big Data geht es eigentlich “nur” um Daten – einfach gesagt. Aber was sind Daten? Daten sind Antworten aus Messungen, zum Beispiel generieren die Resultate aus Umfragen Daten (Rohstoff). Aber bereits die Frage nach dem Namen einer Person ist eine Messung, welche zu Daten führt. Daten sind Signale, die man aufnimmt, die jedoch nur einen beschränkten Ausschnitt der Umwelt zeigen. Daher sind alle Daten, die man erhebt, “biased”. Und damit nicht genug: Mit jeder Schlussfolgerung aufgrund der Datenanalyse werden wiederum Daten generiert. Hier spricht man vom Data-Measurement-Bias-Circle.
Laufend werden immense Datenmengen generiert. Allein über die Mobile Devices beträgt der weltweite Data Traffic im Jahr 2015 über 6’000’000 Terabytes im Monat. Um ein Gefühl für diese Menge zu erhalten, hier ein Vergleich: 1 Terabyte entspricht rund 920 Mio. vollgeschriebenen Buchseiten. Den grössten Beitrag dazu tragen die Smartphones. Dadurch nimmt die Datenmenge exponentiell zu.

In Unternehmen wurden früher Daten in einzelnen Abteilungen gespeichert; meistens sind diese wieder in einer Schublade “verschwunden”. Später hatte man mehr Datenzugriff, aber die Dateien waren extrem strukturiert und deshalb praktisch nicht veränderbar. Heute hat man unzählige strukturierte und unstrukturierte Daten aus allen möglichen Quellen zur Verfügung, die man zusammenfassen kann. Daher hat man die Möglichkeit, besser Wissen aus den Daten zu ziehen und so sogar “Vorhersagen” zu machen, zum Beispiel in Bezug auf das Kaufverhalten.
Mit Big Data kann man Informationen aus Daten ziehen und strategisch verwenden. Wichtig dabei ist, dass man nicht die Technologie, sondern das Business an erste Stelle stellt. Beispiel: Zuerst legt man fest, welche Daten für das Business gebraucht werden und erst in einem nächsten Schritt überlegt man sich, mit welcher Technologie diese Daten gewonnen werden können.
Früher waren die Zahlen und Statistiken stark vergangenheitsbezogen. Heute versucht man mittels Predictive Analytics mit Vergangenheitsdaten und erarbeiteten Modellen Aussagen für die Zukunft zu machen, zum Beispiel mit welcher Wahrscheinlichkeit ein Kunde kündigen wird. Diese Modelle können aber nicht die Zukunft voraussagen. Dies, weil das Modell nur so gut ist, wie es gefüttert wurde. Wenn aber zwischenzeitlich Veränderungen auftreten, die nicht in das Modell eingeflossen sind, stimmen die “Vorhersagen” nicht mehr – zum Beispiel bei einem Börsencrash aufgrund von unvorhersehbaren politischen Veränderungen.
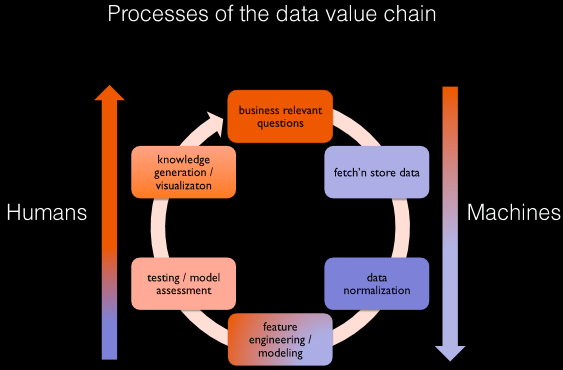
Im Prozess der Datenwertschöpfungskette muss der Mensch sich zunächst bewusst werden, welche businessrelevanten Fragen beantwortet werden müssen. Die Daten müssen dann so strukturiert werden, dass die Maschine diese versteht. Durch die Zuweisung von Attributen wird festgehalten, was wichtiger und was weniger wichtig ist. Die Maschine generiert die entsprechenden Daten. Der Mensch muss nun das Modell mit weiteren Daten füttern und trainieren, damit dieses lernen kann. Es wird Wissen generiert und visualisiert. Auch diese Schritte werden schlussendlich von Menschen durchgeführt. Somit unterstützen uns die Maschinen bei der Big Data Analyse enorm, aber der Mensch ist nach wie vor unerlässlich und wird es voraussichtlich auch in Zukunft bleiben.
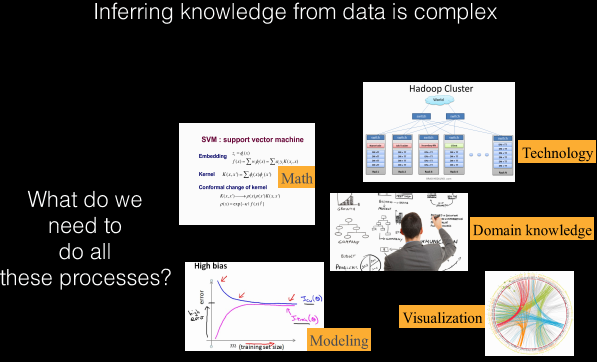
Um Big Data erfolgreich betreiben zu können, müssen in einem Unternehmen zahlreiche Disziplinen kompetent abgedeckt werden. Diese können unmöglich von einer einzelnen Person beherrscht werden.
Daher liegt die Herausforderung darin, ein kompetentes Big Data Team aus fünf bis acht Personen zusammenzustellen, welche die gleiche “Sprache” sprechen. Man muss sich auch gut überlegen, wo das Team im Unternehmen angesiedelt wird: pro Unternehmensbereich dezentralisiert, oder als “Servicecenter” für alle Bereiche, oder gar als eine komplett eigene Einheit. Was aber vor allem wichtig ist, ist dass das Team die nötigen Entscheidungskompetenzen erhält, um auch effektiv tätig sein zu können.
In erster Linie muss die User Experience auf dem mobilen Produkt so gut sein, dass der Nutzer dieses gerne und häufig verwendet.
Ein sehr gutes Beispiel dafür ist “Strava”. Diese Firma wurde 2009 gegründet und hat einen extremen Zulauf erfahren. Das Produkt unterstützt die Velofahrerin auf einfache Art und Weise beim Training. Die Trainingsdaten (Strecke, Zeit, etc.) werden vom mobile Device detailliert aufgezeichnet und in Echtzeit ohne das Zutun des Users automatisch geliefert. Die Daten werden von allen Usern gesammelt und so erhält der User die Möglichkeit, sich mit anderen Usern zu vergleichen. Man sieht in Echtzeit, wo auf der Welt Daten gerade hochgeladen werden. Und dadurch, dass Strava die Trainingsdaten des einzelnen Users kennt, können ihm auch passende Trainingsvorschläge unterbreitet werden.
Fazit: Das Produkt ist einfach zu handhaben, unterstützt den User und gibt ihm Vergleichsmöglichkeiten. Somit ist die Akzeptanz sehr gross für die Nutzung und die Freigabe von Daten.
Nein, die künstliche Intelligenz wird nicht Realität werden, sondern ist bereits heute in unserem Alltag angekommen. Zur Artificial Intelligence gehören zum Beispiel die Gesichts- und Objekterkennungen wie bei Facebook, die Spracherkennung wie bei Siri oder Empfehlungstechnologien wie bei Netflix.
Bis 2007 war Netflix ein erfolgreicher Ausleih-Service, der US-Kunden per Post mit DVDs versorgte. Inzwischen ist das Unternehmen aus Kalifornien zu einem Unterhaltungskonzern gewachsen, der hauptsächlich Filme und Serien im Stream anbietet und eigene Serien produziert.
Netflix nutzt in hohem Masse Big Data und setzt darauf basierend auf Empfehlungstechnologie. Im Jahr 2007 hat Netflix dafür dem Entwickler des besten Algorithmus 1 Mio. Dollar Belohnung bezahlt. Somit kann nun Netflix mit einer hohen Wahrscheinlichkeit dem User vorhersagen, welcher Film ihn als nächstes interessieren könnte und kann so einen passenden Vorschlag unterbreiten. Mit dieser Technologie ist es Netflix bildlich gesprochen gelungen, aus dem Horrorfilm von 1997 “Ich weiss, was Du letzten Sommer getan hast” den Film “Ich weiss, was Du nächsten Sommer tun wirst” zu kreieren. Dafür sammelt Netflix laufend Benutzerdaten des Users, wie zum Beispiel Geschmack, Inhalt, letzte angeschaute Filme, Ratings, Präferenzen, etc. Die Daten, die der Nutzer selber hinterlegt, werden zudem mit dem effektiven User-Verhalten verglichen. Auch Social Support wird für die Datengewinnung beigezogen. Zudem wird bei der Empfehlung darauf geachtet, Wiederholungen zu vermeiden.
Der Erfolg von Unternehmen wird in Zukunft noch stärker davon abhängen, wie gut die Kundendaten ausgewertet und wie diese im Sinne des Nutzers oder der Nutzerin eingesetzt werden. Gleichzeitig wird die Herausforderung aber auch darin bestehen, die Datenschutzbestimmungen, die strenger werden, einzuhalten (siehe Facebook-Urteil vom Europäischen Gerichtshof im Oktober 2015).
Unser Newsletter liefert dir brandaktuelle News, Insights aus unseren Studiengängen, inspirierende Tech- & Business-Events und spannende Job- und Projektausschreibungen, die die digitale Welt bewegen.