AI Anwendungen – Realität oder Fiktion
Juni 1, 2020
Das Thema vom heutigen Nachmittag am Donnerstag, den 14. Mai 2020 um 13:00 Uhr: AI Anwendungen – Realität oder Fiktion.
Die Inhalte diese Blog-Beitrags:
Big Data wird häufig mit dem 3V-Modell beschrieben. Seine 3 Bereiche sind Volume (stetig wachsende Datenmenge), Velocity (Veränderung der Daten in immer kleineren Zyklen), und Variety (mehr und mehr unterschiedliche Daten). Während diese Beschreibung soweit zutrifft, sind vor allem die Wörter “Big” und “Volume” subjektiv und irreführend. In der Tat werden mehrere Millionen Daten für gewisse Anwendungen verwendet, in anderen Fällen wird schon mit 100 Daten erfolgreich gearbeitet. Des weiteren geht es ja nicht darum, möglichst grosse Datenmengen zu erfassen. Es geht viel mehr darum durch die Nutzung der Daten einen Wert für ein Unternehmen zu generieren. Simon definiert Big Data daher wie folgt:
“Big Data ist eine Auswahl an Methoden und Werkzeugen, die zur datenbasierten Wertschöpfung genützt werden.“
AI ist dieser Tage ein grosser Hype. Viele Unternehmen möchten dazu gehören und haben grosses Interesse daran, mit dieser Technologie zu arbeiten. Dass es dazu kommt muss aber zuerst ein Business-Case identifiziert werden, welcher sich für den Einsatz von AI eignet und dem Unternehmen einen Mehrwert bietet.
Simon hat uns 3 unterschiedliche Wege zur Entwicklung eines Business Case für das eigene Unternehmen vorgestellt.
Sobald das Problem erkannt ist, ist die Umsetzung relativ einfach: Erstellen einer Liste mit Lösungsmöglichkeiten, Priorisierung der Liste, Erstellen eines funktionierenden Prototypens und schliesslich die Implementierung.
Gerade in Bereichen mit Texten und Bildern, wie z.B. Websites, Offerten & Rechnungen, Support & Foren, Brochüren, gibt es vielfältige Einsatzmöglichkeiten von AI Anwendungen, z.B. durch Sentiment Analyse, Natural Language Processing (NLP), Optische Zeichenerkennung (OCR) und andere.
Stellt euch die Frage: Welche Prozesse führt das Unternehmen aus und können durch AI unterstützt werden? Auch bei diesem Ansatz können alle Bereiche eines Unternehmens unter die Lupe genommen werden. Sowohl interne Prozesse, wie z.B. Lohnbuchhaltung, Produktdefinition, etc., als auch externe Prozesse, wie z.B. Kundensupport, Reperatur-Servic, Offerten-Management, etc. können mit dieser Methode analysiert werden.
Bei diesen Projekten geht es in der Regel darum, die Effizienz des Unternehmens zu steigern. Oft geht es dabei darum, mehr oder weniger einfache Entscheidungen vom System treffen zu lassen.
Der Entscheidungsprozess selbst kann mit einem Modell von John R. Boyd aus seinem Buch “The Essence of Winning and Losing” beschrieben werden. Es gibt darin die passive Phase, in der Beobachtet und sich Orientiert wird, und die aktive Phase, in der Entschieden und dann entsprechend Gehandelt wird.
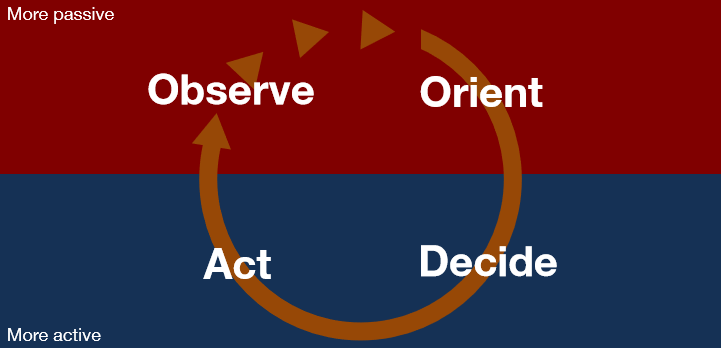
Dazu ein Beispiel:
Observe – Ein Kunde macht weniger Transaktionen als im vorherigen Monat
Orient – Andere Kunden mit diesem Verhalten haben gekündigt
Decide – Wollen wir diesen Kunden behalten? -> Ja!
Act – Dem Kunden ein Geschenk schicken
Die Umsetzbarkeit daraus entstehender Ideen kann mit zwei Skalierungsfragen überprüft werden:
Im oben aufgeführten Beispiel ist es zum Beispiel von entscheidender Bedeutung, dass alle Daten, die für die Entscheidung benötigt werden, zu einem Zeitpunkt verfügbar sind, wo der Kunde noch nicht gekündigt hat. Die Verfügbarkeit und Verarbeitung der Daten muss also früh genug geschehen, dass die daraus resultierende Handlung erfolgreich sein kann.
Mit der Visualisierung von Daten können z.B. Korrelationen für den Menschen sichtbar gemacht werden. Diese sind besser vorstellbar und führen sehr oft zu neuen Projekt-Ideen. Wichtig für ein erfolgreiches Visualisierungs-Brainstorming ist es, die richtigen Menschen zusammen zu bringen. Es braucht dazu natürlich Menschen, die mit Daten umgehen können. Wichtig sind aber auch Menschen, die den jeweiligen Markt, die verschiedenen Stakeholder und ihre Bedürfnisse verstehen, wie auch Menschen, die mit Visualisierungs-Tools umgehen können.
Während so eines Visualisierungs-Brainstormings wird direkt mit den Daten gearbeitet, es werden Fragen gestellt und versucht zu beantworten, Hypothesen definiert und getestet, was zu neuen Fragen und Hypothesen führt. Nach und nach entstehen so immer neue Ideen. Doch Vorsicht, das arbeiten mit Daten braucht Geduld und Ausdauer.
Ein Beispiel: Analyse zur Nutzung von Leihvelos. In den Nutzungsdaten von Leihvelos wurde nach Korrelationen gesucht. Die Visualisierung der Fahrten auf einer Karte erlaubte es so, 3 Hauptnutzungs-Arten der Leihvelos zu identifizieren:
So hat das Leih-Unternehmen, basierend auf den Daten, spezifische Angebote ausgearbeitet.
Die Phase von Fiktion ist vorbei. AI ist Realität und als Werkzeug nicht wegzudenken. Die Erwartungen an AI in Bezug auf menschliche Intelligenz sind in vielen Fällen überzogen. Trotzdem wird der Einsatz von Machine learning über die Zeit zur Selbstverständlichkeit, über die in Zukunft nicht mehr gross gesprochen werden wird.
Dazu einige reale Anwendungen
Ein Modell wird basierend auf historischen Daten gebaut. Es soll von gemachten Kündigungen lernen und so neue Kündigungen vorhersagen. Das Modell wird dann gegen aktuelle Kündigungen getestet. Die Auswahl der Trainingsdaten ist essentiell und bestimmt die Qualität des Modells. Auch hier ist es entscheidend für den Erfolg, dass die Vorhersage des Kündigungstages vor dem Beginn der Kündigungsperiode gemacht werden kann. Das Risiko für solch ein Projekt ist klein, da bei einem Misserfolg die Situation wie heute bleibt, also keine Verschlechterung eintritt.
Ein Kunde hat eine bestimmte Anfrage, die von einem Sachbearbeiter mit einem bestimmten Fachwissen bearbeitet werden muss. Es ist oft ein mühsamer Prozess, diesen Sachbearbeiter ausfindig zu machen. Häufig wandert die Anfrage von Person zu Person, bis sie bei der richtigen Person ankommt. Das Ziel dieser Anwendungen ist es, eine Anfrage direkt an die richtige Person zu senden. Das es sich um zu verarbeitenden Text geht, kommt hier NLP zum Einsatz. Auch bei diesem Projekt ist das Risiko klein, die Situation kann nicht verschlechtert werden.
Der Eigentümer möchte sicherstellen, dass alle Wohnungen im Gebäude jederzeit vermietet sind. Das erstellte Modell hilft der Verwaltung bei der Optimierung der Auslastung. Neben den Vertragsdaten und persönliche Daten vom Mieter, wurden zusätzliche Informationen von anderen Mietern, zum Gebäude selbst, aber auch von Gebäuden und Mietern aus der Umgebung mit einbezogen. Die erreichte Genauigkeit ist relativ tief, da viele äussere Faktoren die tatsächliche Mietdauer beeinflussen. Doch auch hier ist der mögliche Schaden durch das Modell äusserst klein, weshalb die Anwendung trotzdem zum Einsatz kommt.
An einem Spital wurde untersucht, ob AI bei der Diagnose einer seltenen Krankheit unterstützen kann. Auf Grund der seltenen Krankheit stand nur kleines Datenset aus Blutdaten von 100 Personen zur Verfügung. Für die Diagnose ist eine hohe Genauigkeit zwingend, da die Risikon enorm hoch sind:
Daher können solche Anwendungen auch bei recht hoher Genauigkeit die Diagnose eines Arztes nicht ersetzen, sondern nur unterstützen.
Jede einzelne Windturbine liefert in Echtzeit eine Menge and Daten von unterschiedlichsten Sensoren. AI überwacht diese Werte kontinuierlich und zeigt Potential zur Verbesserung an. Alle vom Modell bisher analysierten Windparks haben ein Potential zur Verbesserung von 10 – 15%!
Zunächst eine Übersicht über die verschiedenen Methoden, die wir im Zusammenhang Machine learning kennen:
In der Folge werden die Vorteile einiger wichtiger Methoden und Algorythmen genauer erläutert.
Bei der Regression gibt es die lineare und polynomale Regression. Zur Bewertung eine Regressionsmodells wird die Summe der Abstände zwischen der brechneten Kruve und den Messpunkten berechnet. Ein aktuelles Beispiel für die Regression ist die Vorhersage von Corona-Toten anhand von aktuellen Zahlen.
Entscheidungsbäume teilen die vorhandenen Daten automatisch in mehrere Ja/Nein Fragen und kommen so zu ihrem Ergebnis. Sie haben den grossen Vorteil, dass sie sehr gut visualisiert werden können und damit einfach nachvollziehbar sind. Daher kommen sie in Anwendungen mit hoher Verantwortung zum Einsatz, z.B. bei der Kreditvergabe.
Die Ensemble oder Boosting Methoden nutzen zum Teil einfache einzelne Modelle oder Algorythmen und kombinieren diese am Schluss für das beste Ergebnis. Random Forest macht so mehrere Entscheidungsbäume und kombiniert diese dann.
Neuronale Netze sind der funktionsweise des menschlichen Gehirns nachempfunden. Erst die Leistung moderner Rechner ermöglicht heute den breiten und effizienten Einsatz dieser Methoden. Neuronale Netze bestehen aus mehreren Neuronen, die mit einander verbunden sind. Wie eine Nervenzelle bekommen die Neuronen über die verschiedenen Verbindungen Signale und entscheiden dann, ob sie das Signal weitergeben oder nicht – der Output ist entweder 1 oder 0. Das Neuron summiert die Werte der verschiedenen Eingänge, addiert einen Offset pro Verbindung und wenn das Ergebnis grösser Null ist, reagiert das Neuron. Es bildet also die Funktion einer Nervenzelle ab.
Wie auch schon bei den echten Fallstudien beschrieben, können die Konsequenzen für einen Fehler im Modell sehr unterschiedlich sein. Bei durch AI gesteurten Waffen oder selbstfahrenden Autos kann die Folge der Tod sein. Hingegen bei automatisierten Schadensprozessen, wird im schlimmsten Fall ein Mensch eingreifen müssen.
In der Experimentierphase geht es darum, ein funktionierendes Modell zu erstellen. Es ist jedoch auch sehr wichtig, ein bereits implementiertes Modell stetig zu überwachen. Ob das Modell funktioniert und weiterhin die gewünschte Präzision liefert muss konsequent kontrolliert werden. Das Verhalten kann sich über die Zeit verändern und das Modell muss dann entsprechend neu trainiert werden. Ein bekanntes Beispiel dafür ist Google’s Anwendung zur Vorhersage der Grippe. Das Modell hat zunächst präzise Vorhersagen gemacht hat, ist dann jedoch massiv abgewichen und musste neu trainiert werde. Auch äussere Einflüsse, wie z.B. Data Poisoning oder Inversion können gegen ein AI Modell eingesetzt werden.
«Machine Learning and Artificial Intelligence systems are stupid. While they are useful tools in the hand of man, blindly following machine recommendations will lead you “into the river”.» Simon Hefti, Jun 19

Photo by Keenan Barber on Unsplash
Lesen Sie auch den Bericht über den Vormittag mit Dr. Lisa Falco von Nadine Nyfenegger. Das Thema dort: AI – Die Zukunft der Medizin?
Unser Newsletter liefert dir brandaktuelle News, Insights aus unseren Studiengängen, inspirierende Tech- & Business-Events und spannende Job- und Projektausschreibungen, die die digitale Welt bewegen.