AI Use Cases – Probleme in Prognosen zerlegen
Mai 7, 2020
Donnerstagmorgen, 24.4.2020, 08:15 Uhr; Unterricht zu AI unter dem Corona-Regime – das heisst, Zoom Videoconferencing. Die Gesichter teils noch verschlafen, den Kaffee in Griffnähe, die Frisuren … naja.
Heute geht es um das Auffinden von Anwendungsfälle für AI und die erforderliche Transformation. Wie lassen sich erkannte Probleme als messbare Prognosen definieren, damit sie mit AI gelöst werden können.
Der Weg dorthin führt über Technik (Einführung), Befähigung (Die Ökonomie von AI), Prozesse & Transformation (Die Anatomie von Tasks) und Übung (Case Study und Präsentation). Soweit die heutige Agenda und Storyline.
Anhand von Beispielen erklärt uns Antonio was er tut und wo, resp. wie er AI einsetzt. Werbungserkennung auf Fernsehbildern, Schadensmeldungen und -abwicklung bei Versicherungen mittels Handyfotos, Einsatz von IoT Sensoren zur Pipeline Überwachung, Prozessoptimierung für Qualitätsprüfungen in der Pharmabranche oder auch Warnsysteme für Sturzfluten. All das kann AI sein. Die Breite der Themen und Erfahrung lässt Spannung zum heutigen Tag aufkommen. Und tatsächlich: anhand Antonio’s Lernzielen dürften wir heute eine etwas andere Sicht auf AI gewinnen – und genau so ist es dann letztlich auch.

Die Übung “Such den Walter” zeigt erneut, was der Mensch intuitiv, auf Anhieb, ohne Training, einfach mit Intelligenz kann und wo die Einschränkungen liegen (Menge, Geschwindigkeit, Qualität, Durchlaufzeit, …). Eine Maschine wir auch auf absehbare Zeit nur das können was ihr beigebracht wurde. Bereits eine kleine Abart von Walter kann für sie problematisch sein. In der Selbstanalyse klären wir, welchen Algorithmus wir selber bei unserer Suche nach Walter angewandt haben. Wir stellen fest, dass Menschen teilweise vergleichbar wie Maschine agieren, jedoch in einigen Bereichen oder situativ auch abweichend. Antonio erläutert Parallelen und Unterschiede anhand der Funktionsweise eines Teils des Gehirns. Unsere ca. 86 Milliarden “Schaltstellen” im Hirn sind einfach einzigartig und genial!
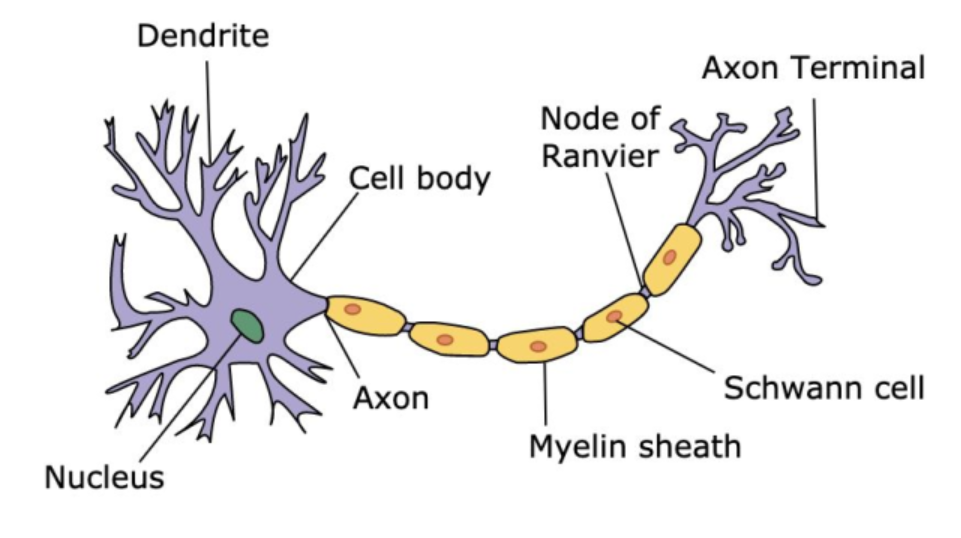
Das Verständnis für die Entwicklung von Software zu AI (AGI vs. AI) sowie deren Parallelen und Unterschiede ist fundamental. Prozessual definierte Abfolgen von Regeln und Funktionen über “Decision Trees” bis hin zu Neuronalen Netzen und Machine Learning (ML) resp. Deep Learning (DL). Die Analogie der Funktionsweise des Gehirns zur Funktionsweise von AI erschliesst sich damit sehr schön. Was diese Neuronalen Netzwerke erst richtig ermöglicht hat … das kommt später!
Ein spannender Exkurs folgt mit dem “Dynamik-Robustheits-Modell“. Stark vereinfacht behandelt es die erforderliche Transformation vom komplizierten, auf Wissen basierten Modell zum vorherrschenden dynamischen, auf Können basierten, sich schnellverändernden Modell unter Komplexität. Wobei, jeder Mensch selber ein komplexes Konstrukt ist, vgl. auch weiter oben. Mehr zum Begründer des Modells, Dr. Gerhard Wohland “Agil: Ein konservativer Ansatz?”.
Schlüsselerkenntnisse:
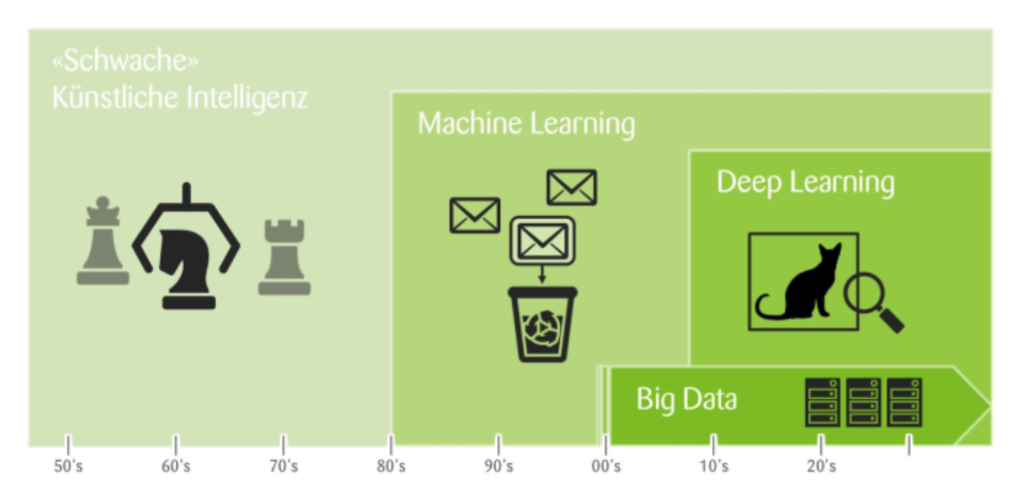
Ein Meilenstein in der AI war ca. 2012 – der Wandel von “Simple Neural Networks” zu “Deep Learning Neural Networks”. Wesentlicher Antrieb und Befähigung war das ökonomische Phänomen, dass das Kosten-Leistungs-Verhältnis von Mikroprozessoren sich markant veränderte. Die Rechenleistung eines ipad’s von 2010 kostete 1970 noch ca. 100 Mio USD. Jedoch auch die Menge und Verfügbarkeit von Daten hat sich in der Epoche von Big Data exponentiell entwickelt. Software wurde erheblich günstiger, ebenso Rechenleistung. Diese ist heute meist in Form von günstigem Cloud Computing fast unbeschränkt verfügbar. Die Leistungsfähigkeit von Grafikkarten ist exorbitant gestiegen. Selbst Algorithmen sind häufig frei verfügbar, bspw. über GitHub. Diese ökonomischen Aspekte ermöglichten also die eingangs noch unbeantwortete Frage der Befähigung von Neuronalen Netzen für ML und DL. Eine Übersicht über die Ära von Big Data:
Einzelne Unternehmen entwickelten ihre Marktmacht aus der eigenen Position heraus, andere fusionierten oder wurden aufgekauft. Wieder andere wurden von Visionären geführt oder waren einfach zum richtigen Moment im richtigen Markt. Die Gründe für den Erfolg sind breit gestreut. Das Ergebnis sind die heute vorherrschenden Machtverhältnisse. Die Hoheit über Daten und deren Verfügbarkeit bei entsprechender Qualität sind nebst günstiger Rechenleistung zentrale Teile des Erfolgsmodells. Erst die eigenen Daten ermöglichen es ein Geschäftsmodell auch erfolgreich zu verteidigen.
Moore’s Law (Gesetzmässigkeit über die Komplexität der integrierten Schaltkreise) ist elementar für AI. Erst die massiv gesteigerte Leistungsfähigkeit von Prozessoren ermöglichte die aktuelle Entwicklung. Parallel dazu vielen die Kosten für “Computing” zusammen. Zur Veranschaulichung, was die Anwendbarkeit von Moore’s Law auf den Alltag bedeuten würde:
Eine fundamentale Frage der Zukunft ist, wie wir AI als “Prognose-Maschine” einsetzen. Es gilt, die verfügbare Daten und Informationen in brauch- und nutzbare Informationen umzuwandeln. Diese Transformation ist ein Schlüsselelement.
Schlüsselerkenntnisse:
Jede*r von uns kann grundsätzlich AI nutzen, die Technik ist inzwischen sehr billig. Selbst der Zugang zu gewissen Algorithmen ist sehr günstig bis kostenlos möglich. Teilweise bestehen auch grosse, frei nutzbare Datenquellen in Form von “Open Data Sources”. Das bedeutet konkret, dass eine Abgrenzung nur noch über die eigenen Daten resp. das eigene Können möglich ist.
In den Fokus rückt die Frage der Transformation von Problemen in Lösungen mittels AI. Wie kann das heutige IST in Form von verlässlichen Prognosen in ein angestrebtes SOLL gewandelt werden? Wie können also die günstigen Rahmenbedingungen zum eigenen Vorteil genutzt werden? Dies ist das fehlende Puzzleteil des heutigen morgens. Ob der Weg nun das Ziel, oder das Ziel der Weg ist, es führt nichts am richtigen Modell vorbei.
Anhand des unten abgebildeten Modells lässt sich ein Arztbesuch und der dazugehörende Kontext exemplarisch nachvollziehen. Dieses Modell dient uns als Übungsgrundlage und hat sich in den Break-out Sessions als sehr praktikabel und nützlich herausgestellt. Trotz, oder gerade wegen der Einfachheit, zwingt es jedoch auch zu Klarheit.
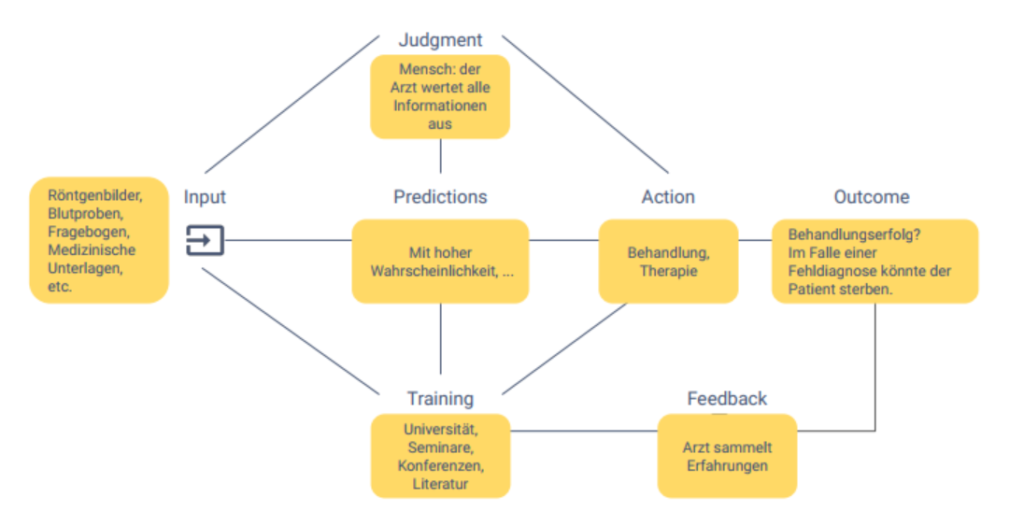
Ziel unserer Case Study ist eine einzelne Entscheidung aus einem übergeordneten Gesamtprozess zu isolieren und dafür einen Lösungsdesign zu entwickeln. Also ab in die Break-out Sessions!
Schlüsselerkenntnisse:
In der Arbeitsgruppe mit Lorand Frank und André Wieler entwickelten wir den nachfolgenden Lösungsansatz. Unsere Erkenntnis: das Modell funktioniert tiptop, jedoch selbst bei vermeintlich einfachen und kleinen Tasks braucht es viel Zeit und Klärung um Schnittstellen, Abhängigkeiten, Einflüsse, u.ä. zu erarbeiten.
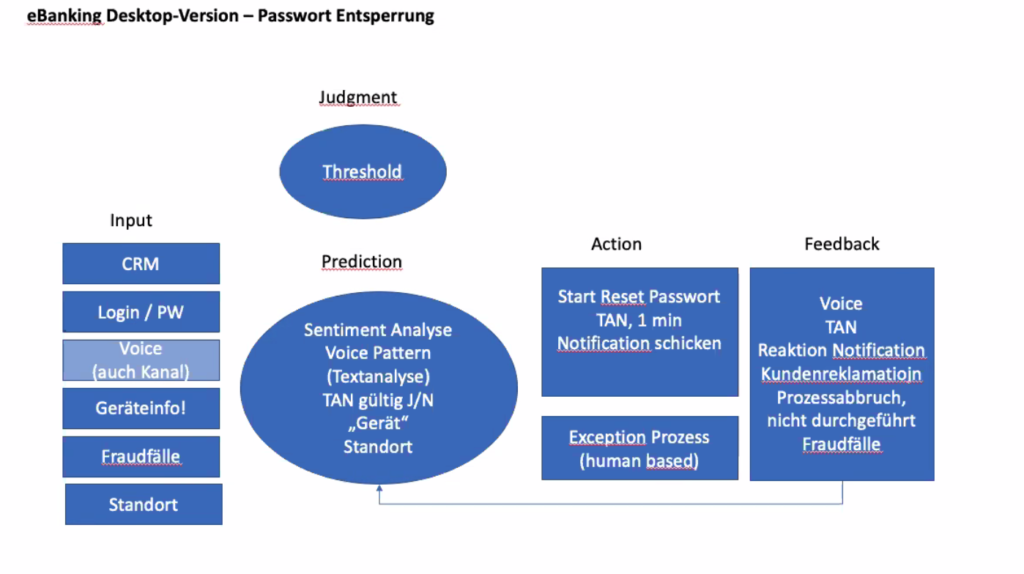
Es war ein intensiver, sehr lehrreicher und mit vielen neuen und vor allem auch praktischen Erkenntnissen, Methoden und “Werkzeugen” bestückter Morgen. Nun steht die Transformation von Wissen in Können an.
Vielen herzlichen Dank an Antonio, dass du dein Wissen, Können und deine Learnings mit uns geteilt hast.
Unser Newsletter liefert dir brandaktuelle News, Insights aus unseren Studiengängen, inspirierende Tech- & Business-Events und spannende Job- und Projektausschreibungen, die die digitale Welt bewegen.