Customer Insights vs. Data Analytics
März 4, 2018
Aus dem Unterricht des CAS Digital Leadership mit Dozent Oliver Staubli (CEO und Data Scientist) berichtet Nuno Felisberto.
Am heutigen Tag erwartet uns das spannende Thema rund um Customer Insights vs. Data Analytics. Beim Thema Data Analytics will Oliver Staubli aufzeigen, was er eigentlich so den ganzen langen Tag für seine Kunden aus vorhandenem Datenmaterial herausholen kann. Als Abschluss werden wir uns in einer Gruppenarbeit anhand einer frei gewählter Aufgabe, als Datenflowarchitekten versuchen.
Als Intro möchte Oliver Staubli von den CAS Absolventen wissen, was für Kunden wir in unserem beruflichen Umfeld haben. Schnell wird klar, dass die Segmentierung anhand von Kriterien gemacht wird und diese je nach Umfeld sehr unterschiedlich ausfallen. Nichtsdestotrotz werden Kundengruppen generell nach ihren Bedürfnissen erstellt. Da das Kundenverhalten sich in den meisten Fällen zurückverfolgen lässt, können so Kundengruppen gebildet werden, welche gemeinsame Charakterzüge der einzelnen Kunden vereinen. Oliver Staubli stellt fest, dass es viele Verantwortliche gibt, welche glauben zu wissen wer ihre Kunden sind, doch im Endeffekt dies nicht der Realität entspricht. Hier kann der Data Scientist mit seinem Wissen erfolgreich Entwicklungsarbeit leisten.
Das Aufgabengebiet umfasst generell 4 Hauptthemen. Diese gliedern sich wie folgt:

Eine Kohorten-Analyse gibt primär Auskunft, wie loyal unsere Kunden sind. Am angefügten Beispiel kann herausgelesen werden, was der Umsatzanteil von Neukunden ausmacht.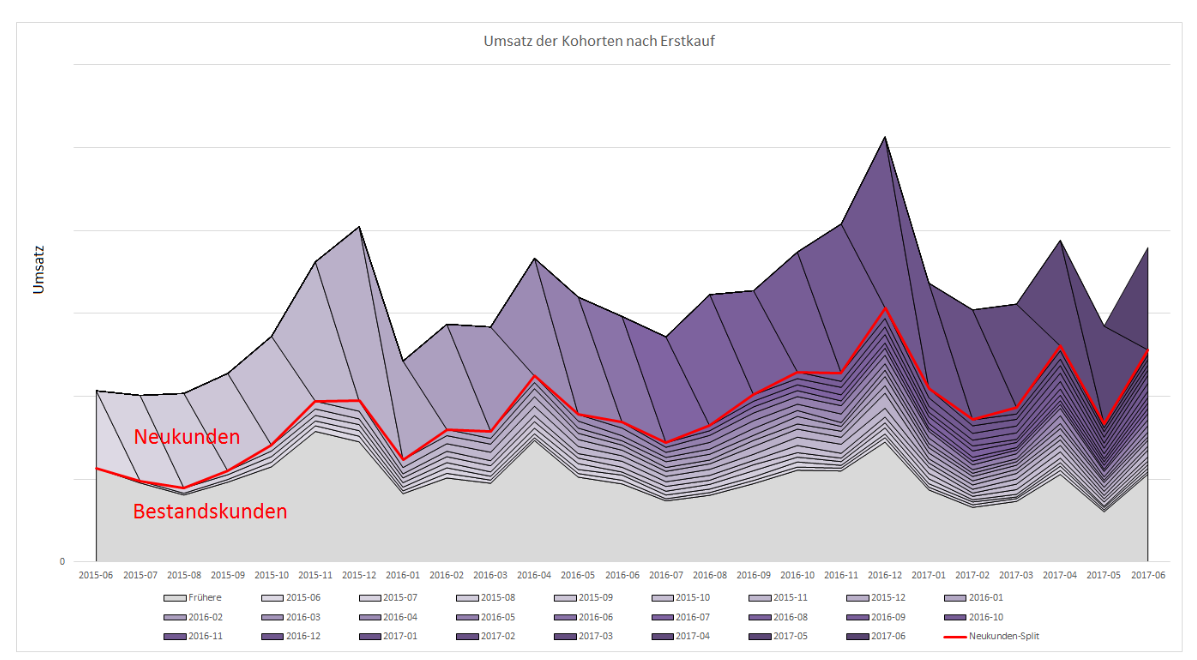
Weitere Beispiele von Fragen zur Kohorten-Analyse:
Oliver Staubli sagt aus, dass ein bestehender Kunde 5 – 7 mal mehr an Umsatz einbringt, als ein Neukunde. Über die Zeit hinweg zahlt die Loyalität sich entsprechend aus und der Aufwand um einen bestehenden Kunden zu halten sinkt entsprechend.
Somit sind Bestandskunden 5 bis 7 mal wertvoller als Neukunden. Trotz dieser Tatsache priorisieren viele Firmen noch immer die Neukunden-Gewinnung auf Kosten des Bestandskunden-Marketings. Schon 2011 stellte Forrester in einer Studie fest, dass im Einzelhandel fast 80 % der Budgets für digitales Marketing in die Akquise von Neukunden fließt.
Dass sich an diesem Missverhältnis in den letzten fünf Jahren noch nicht viel geändert hat, sieht man gut am gleichbleibend hohen Stellenwert der Conversion Rate für Firmen als Key Performance Indicator (KPI). Ganz im Gegenteil zum selten erhobenen KPI der Retention Rate, sprich wie viele Kunden über die Zeit gehalten werden können. Für den optimalen Marketing-Mix mit dem höchsten Return On Investment (ROI) müssten aber beide KPIs gleichzeitig optimiert werden.
Den Wert von Bestandskunden, d.h. Wieder- und Stammkäufer, analysierte Adobe 2012 in einer breit angelegten Studie mit anonymisierter Daten von 33 Mrd. Besuchen bei 180 Onlineshops in den USA und Europa. Hier die Kernaussagen der Studie:
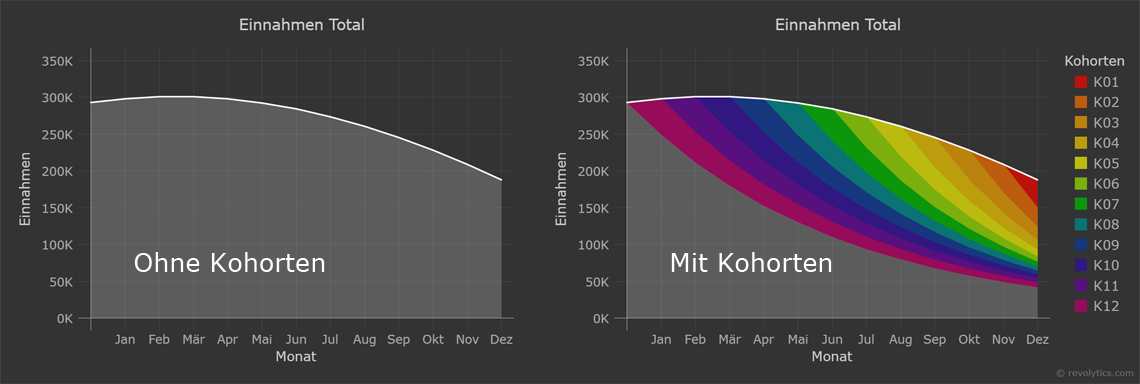
Die Kohortenanalyse bietet einen visuellen Zugang zur oben genannten Marketing-Mix-Optimierung und zeigt einfach auf, wie sich die Einnahmen bezüglich Neukunden und Bestandskunden über die Zeit entwickeln. Gleichzeitig lassen sich darin sehr leicht Erfolg und Misserfolg von Marketing-Kampagnen ablesen.
Zuerst aber zur Definition von Kohorten: Eine Kohorte ist eine Gruppe von Kunden mit einer gemeinsamen Eigenschaft oder Erfahrung in einer definierten Zeitperiode. Im folgenden Beispiel werden Kunden mit demselben Akquisitionsdatum bzw. Akquisitionsmonat zur gleichen Kohorte gezählt. Es könnten aber auch demografische Eigenschaften wie Alter, Geschlecht, Mobile-/Desktop-Zugriff, etc. verwendet werden. Mit der Kohortenanalyse können darauf verschiedene KPIs dieser Kohorten wie z.B. Einnahmen, Anzahl Kunden, Retention-Rate, Conversion-Rate, u.a. analysiert und visualisiert werden. Mit Hilfe der Kohortenanalyse kann also das Verhalten von Kundengruppen über die Zeit abgelesen werden.
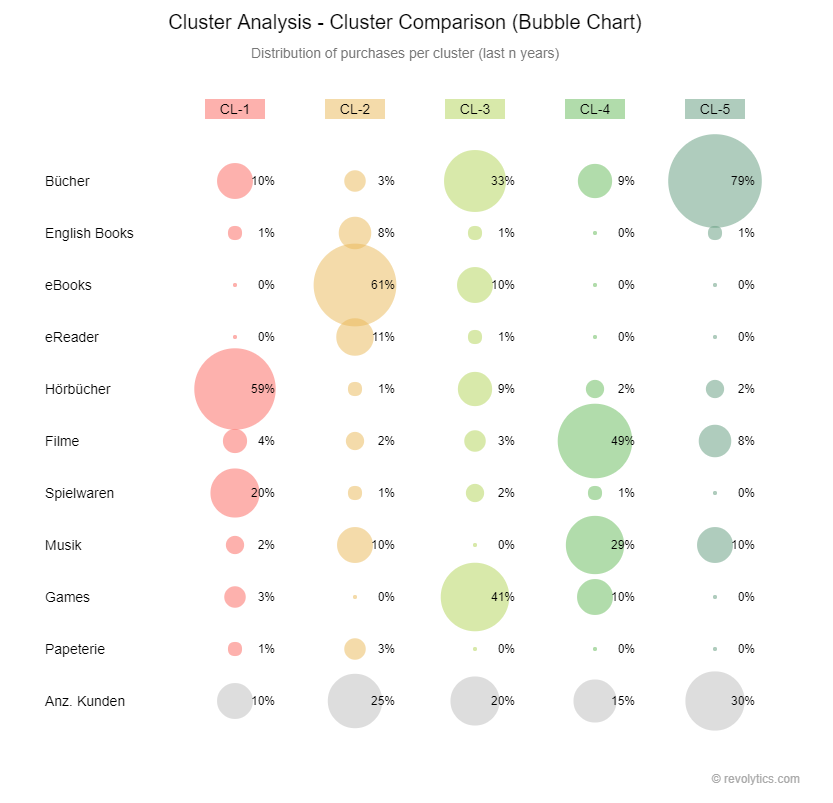
In der Clustanalyse bildet man aufgrund von Daten entsprechende Personas ab. Diese Art der Gruppierung wird erarbeitet, um den Kunden möglichst gut abzubilden und einzuordnen. Generell wird der Output der Clusteranalyse für die Generierung eines Profils verwendet, damit im Anschluss mit beliebigen Dimensionen die Kundengruppen visualisiert werden können.
Beispiel der Abgrenzung zwischen den Kundengruppen einer Buchhandlung:
 Machine Learning
Machine LearningOliver Staubli sagt aus, dass traditionelles Programmieren hingeht und den Code erstellt, so dass die gewünschten Funktionen ausgeführt werden. Beim Machine Learning generiert ein Programm Daten, welche aus einem System / DB kommen, welche wiederum vorgängig programmiert wurde.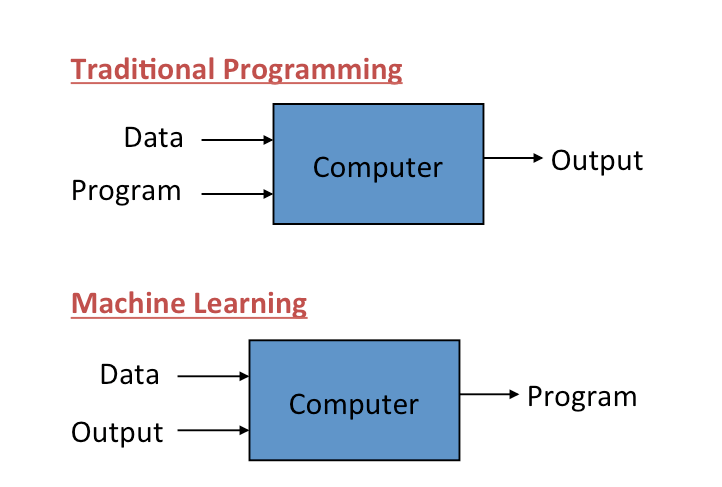
Es gibt drei übergeordnete Themengebiete im Bereich Machine Learning. Die drei Themengebiete werden wie folgt unterteilt:
Der Lernalgorithmus versucht eine Hypothese zu finden, um eine möglichst zielsichere Voraussage zu treffen. Die Methode richtet sich also nach einer im Vorhinein festgelegten zu lernenden Ausgabe, deren Ergebnisse bekannt sind. Liegen die Ergebnisse der Ausgabe in einer kontinuierlichen Verteilung vor, sprich handelt es sich bei den Ergebnissen, um eine Vielzahl von quantitativen Werten – spricht man von einem Regressionsproblem. Liegen die Ergebnisse hingegen in diskreter Form vor bzw. sind die Werte qualitativ, so spricht man von einem Klassierungsproblem.
Der Lernalgorithmus versucht in den Daten Muster zu erkennen und solche die von den Mustern abweichen. Ein künstliches neuronales Netz orientiert sich an der Ähnlichkeit zu den Inputwerten und adaptiert die Gewichte entsprechend. Es können verschiedene Dinge gelernt werden, wie beispw. die automatische Segmentierung oder die Komprimierung von Daten zur Dimensionsreduktion.AI
Der Lernalgorithmus steht für eine Reihe von Methoden des maschinellen Lernens, bei denen ein AGENT selbständig eine Strategie erlernt und so versucht seine Belohnung zu maximieren. Hierbei wird dem AGENT nicht vorgezeigt, welche Aktion in welcher Situation die beste ist, sondern er erhält zu bestimmten Zeitpunkten eine Belohnung, die auch negativ sein kann. Anhand dieser Belohnungen nähert er bspw. eine Nutzenfunktion dem Wert an, welcher zu diesem Zeitpunkt oder zu welcher Aktion geführt hat.
AI ist ein Roboter, welcher versucht so zu agieren und reagieren, als sei er ein Mensch. AI integriert Deep Learning und Machine Learning gleichermassen. Roboter werden keine eigenen Codes schreiben, sondern lernen aus den Verbindungen und sind so in der Lage diese zu interpretieren / daraus zu lernen.
Data – Flow – Map Beispiel (Gruppe 1):
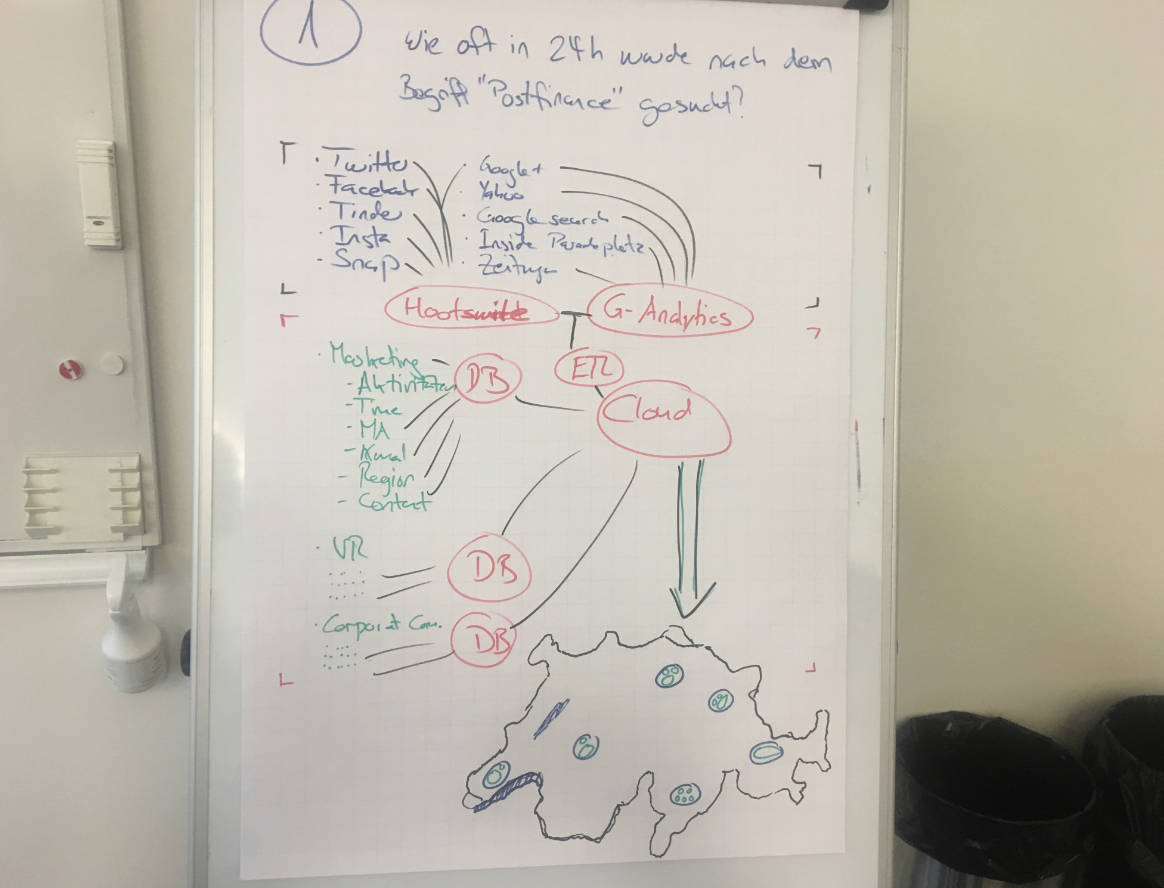
und ein professionelles Data – Flow – Map vom Profi himself:
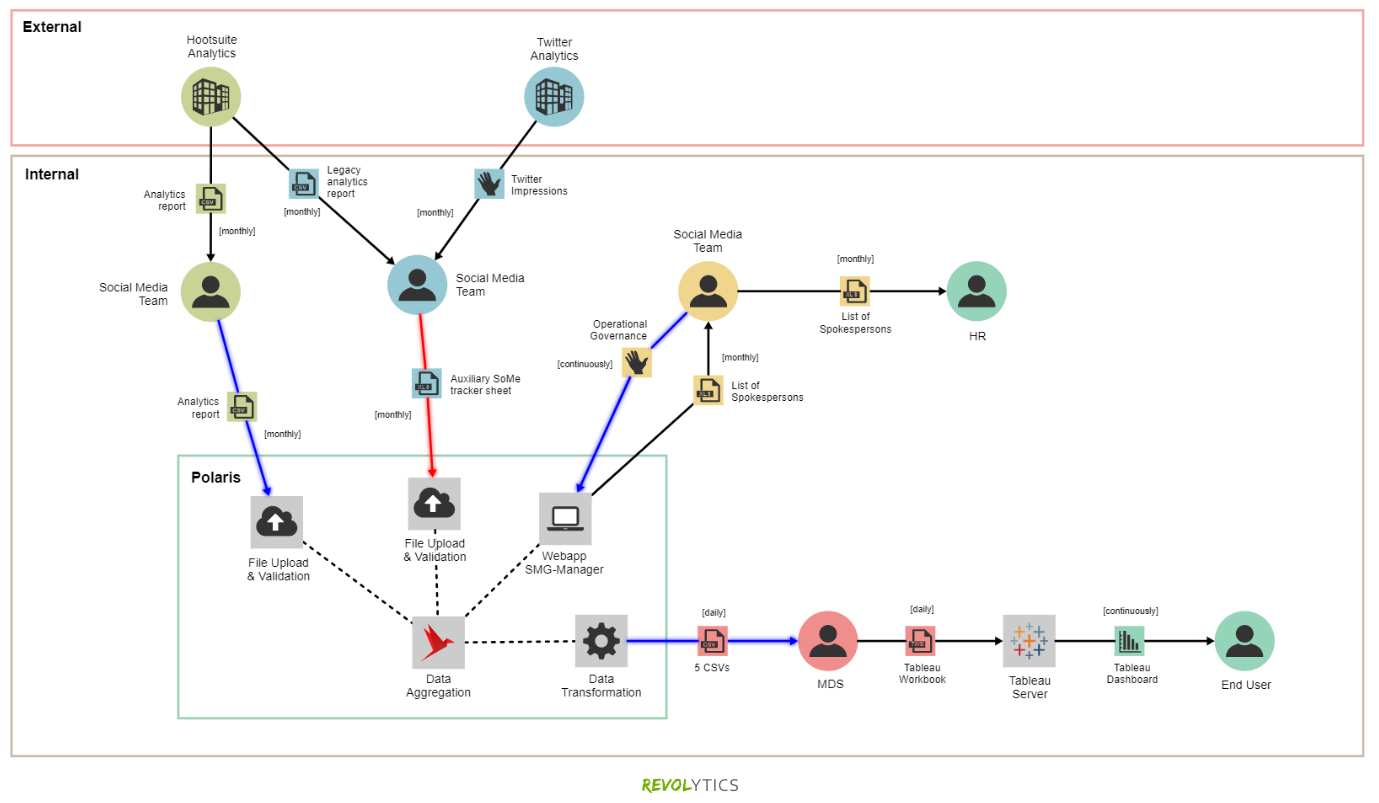
Viele Daten sind nicht strukturiert und müssen vorgängig gehandelt, so dass sie weiterverwendet werden können. Es gibt unterschiedliche Protokolle und DB mit Schnittstellen, welche nicht untereinander verbunden sind. Diese Situation muss den Verantwortlichen klar gemacht werden, so dass der GAP zwischen IST und SOLL sichtbar und die nötige Entwicklung angestossen wird.
Der Beruf des Data Scientist ist vielfältig und hat viel mit Visualisierung und Kommunikation zu tun – ein Beruf mit Zukunft!
Unser Newsletter liefert dir brandaktuelle News, Insights aus unseren Studiengängen, inspirierende Tech- & Business-Events und spannende Job- und Projektausschreibungen, die die digitale Welt bewegen.