Come Down To Earth. Real Data Science Projects. Case Studies
Dezember 12, 2016
Aus dem Unterricht des CAS Disruptive Technologies mit Simon Hefti berichtet Sandro Santostefano:
Unser Dozent, Simon Hefti, führt eine Firma für datenbasierte Wertschöpfung. Als Unternehmer und Business Scientist begleitet er Kunden aus unterschiedlichsten Branchen in technischen, konzeptionellen und organisatorischen Fragen. Der Unterricht beinhaltete folgende Themenbereiche:
Big Data lässt sich nach einer „V-Formel“ definieren. Die Begriffe wie Volume, Velocity, Variety, Veracity können mit unterschiedlicher Gewichtung für die Erklärung des Begriffes verwendet werden. Aber letztlich geht es alleine darum einen Wert zu generieren. Big Data liefert uns die Methoden und Werkzeuge, um einen datengetrieben Wert zu generieren.
Wie sieht der Geschäftsprozess in einem datengetriebenen Projekt aus?
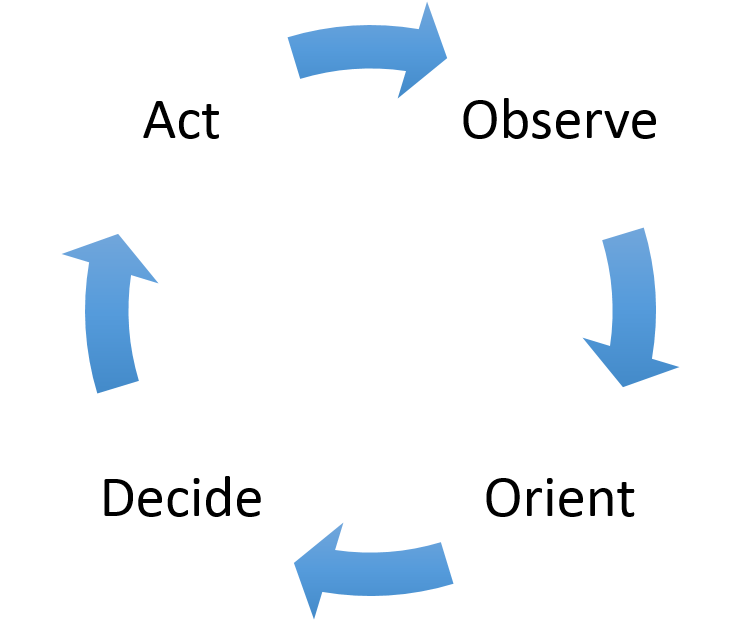
Ich überprüfe die Daten und verschaffe mir einen guten Überblick. Als Beispiel könnten das, alle Transaktionsdaten sein, die ein Kunde mit dem Anbieter generiert.
Ich gewinne die Erkenntnisse die ich für eine Entscheidungsfindung benötige. Z.B. ist es ein guter Kunde oder besteht die Gefahr einer Kündigung etc.
Aus den Analysen leite ich die Entscheidungen ab. Z.B. Wir müssen diesen Kunden behalten etc.
Die Entscheidungen werden nun umgesetzt. Z.B Wir senden dem Kunden ein Geschenk oder rufen ihn in Sinne einer Kundenzufriedenheitsumfrage an.
Wichtig: Das Muster muss wiederholt werden, damit die Erkenntnisse aus einer neuen Datenanalyse den Anstoss für weitere Verbesserungen genutzt werden können. Wenn man sich in einen solchen Prozess befindet, gibt grundsätzlich zwei Skalierungsprobleme:
Als einfaches Bespiel:
Wenn man von einem Kündigungsabwehrprozess bei einem Telefonieunternehmen ausgeht, wäre das dümmste was passieren kann, dass die Kunden über die Kündigungsmöglichkeiten aktiv informiert werden. Die Entscheidung den Kunden behalten zu wollen und ihn zu kontaktieren könnte in der falschen Zeitskala des Prozesses dazu führen, dass die Kündigungsfristen in Erinnerung gerufen werden.
Bei solchen Fragen kann man einen Blick auf die eigene Prozesslandschaft werfen, um herauszufinden ob gewisse datenbasierten Prozesse und Auswertungen uns die Antwort liefern können.
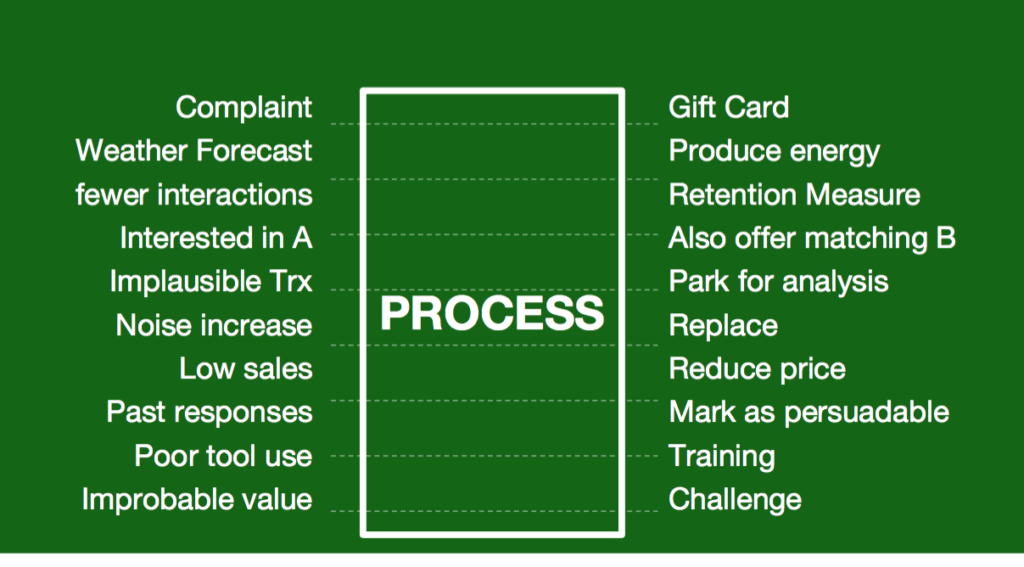
Nehmen wir das Beispiel der Reaktion auf eine Reklamation. Dieser Prozess ist gut bekannt. Es geht darum, schnell und angemessen zu reagieren und so das Problem – ein unzufriedener Kunde – in eine Gelegenheit – einen Fan – zu drehen.
Das funktioniert nur, wenn der Reklamationsprozess schnell genug ausgeführt wird; genau gesagt muss der Prozess auf der Zeitskala des zu Grunde liegenden Vorgangs ausgeführt werden. Die schnelle Ausführung bedeutet, dass die Entscheidungsgrundlagen und idealerweise ein Vorgehensvorschlag rechtzeitig vorliegen müssen. Und beides erfolgt datenbasiert.
Natürlich ist der Reklamationsprozess nur eines von vielen Beispielen. Die Prozesse sind unterschiedlich doch letztendlich geht es immer darum, die Dinge richtig zu tun und die richtigen Dinge zu machen und beides lässt sich mit datenbasierten Prozesse schnell und automatisiert ausführen.
Es gibt eine Reihe von verschiedenen Algorithmen und Tools, die solche datenbasierten Auswertungen ermöglichen, immer mit dem Ziel, die gewonnenen Erkenntnisse für die Zukunft anwenden zu können. Nachstehende eine Übersicht der Tools oder Algorithmen:
Der Ablauf ist immer gleich. Man geht zurück in die Vergangenheit und versucht mit Daten herauszufinden, ob man das voraussagen hätte konnte. Dieses Muster wendet man dann mit den heutigen Daten an.
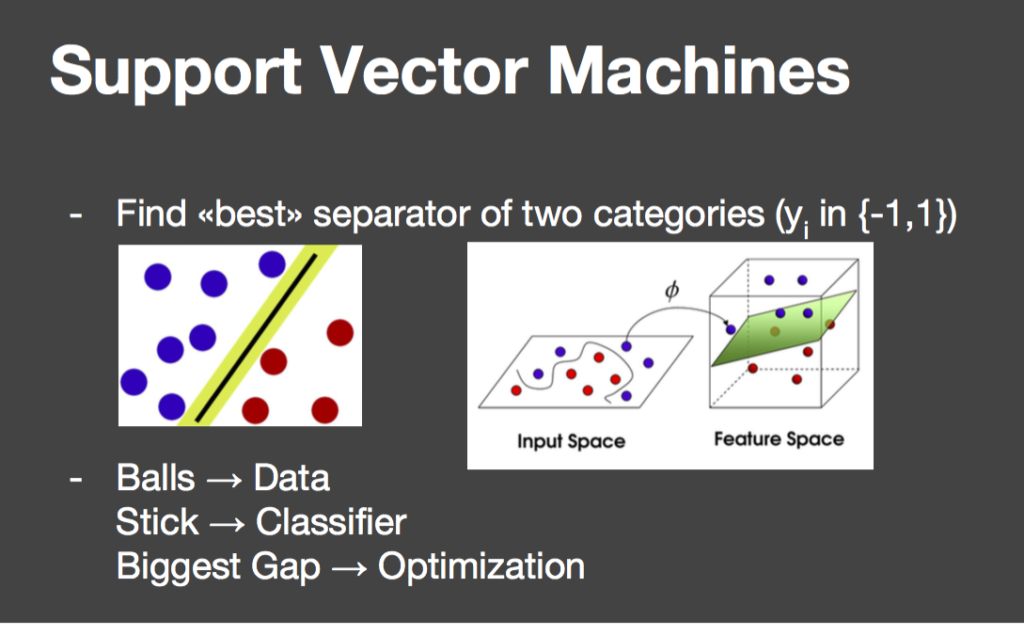

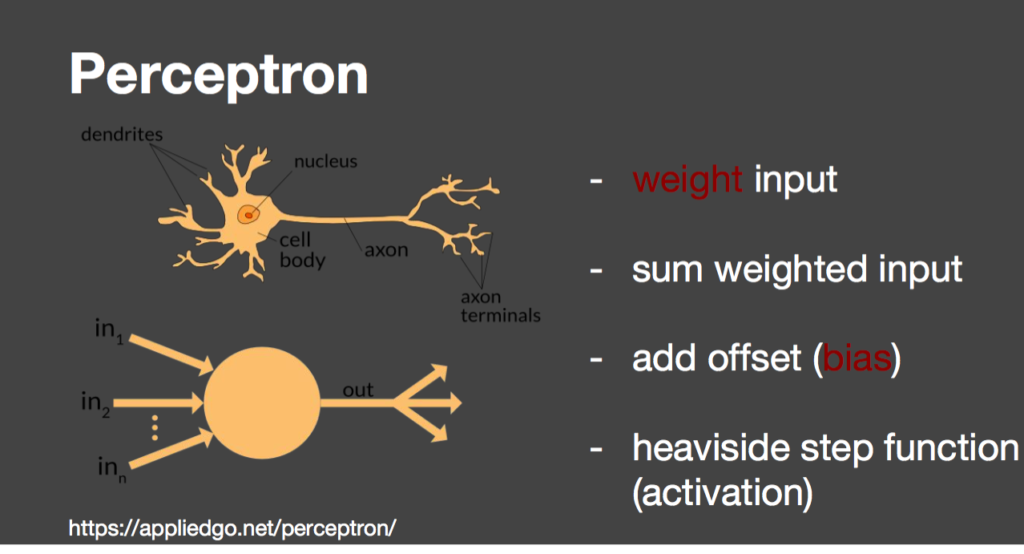
Aber wie packt man denn Big Data richtig an? Es geht um die vier Bereiche: Daten, Technologie, Wert & Wirkung sowie Menschen & Kultur. Wenn diese vier Bereiche unter Kontrolle sind, kann nichts schiefgehen. Dass Daten eine wichtige Grundlage für die datenbasierte Wertschöpfung sind, ist leicht einzusehen. Damit Daten genutzt werden können, müssen sie Qualitätsanforderungen genügen.
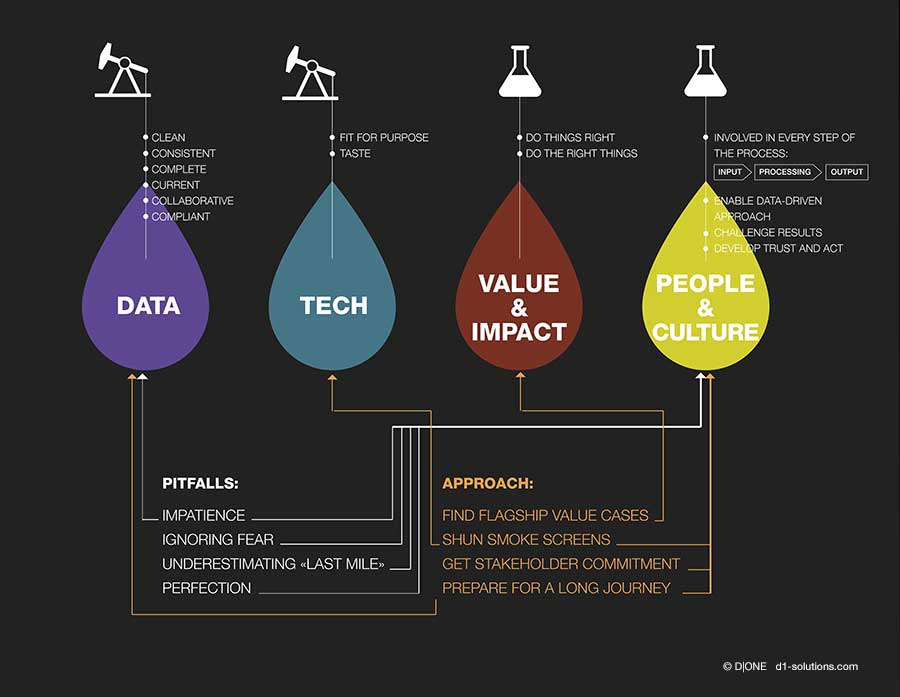
Das gilt unabhängig davon, ob Sie die Daten früh im Prozess auf Qualität hin prüfen, wie das in den klassischen Data Warehouse Systemen erfolgt, oder ob Sie Daten zuerst einmal in eine “Fotoschachtel” werfen und sich erst beim Datengebrauch um die Datenqualität kümmern, wie das im “Big Data” Ansatz oft der Fall ist.

Die Qualitätsanforderungen lassen sich mit den “sechs C” beschreiben. Daten müssen sauber (clean) sein. Sie müssen konsistent sein. Sie müssen vollständig sein (complete). Sie müssen aktuell sein (current). Sie müssen im Team nutzbar sein (collaborative). Und letztendlich müssen sie den regulatorischen Anforderungen genügen (compliant).
Das sind hohe Anforderungen. Sie werden in der Regel nicht auf einmal erreicht. Im Gegenteil: diesem Ziel kommt man asymptotisch näher. Was kein Grund zum Verzweifeln ist: Daten können bereits sinnvoll genutzt werden, wenn die Qualitätsanforderungen noch nicht vollständig erfüllt sind.
Man braucht auch die richtige Technologie. In den vergangenen Jahren war die Diskussion um Big Data von diesem Thema dominiert – dabei ist die Frage im Grunde einfach: die Technologie muss der Aufgabe gewachsen sein und Ihrem Geschmack entsprechen.
Oftmals bleiben Datenprojekt auf der Strecke liegen. Man überlegt ob zu wenig, welchen Wert man eigentlich erreichen möchte und oft werden die Menschen zu wenig einbezogen. Weitere Stolpersteine sind:
Stolpersteine
Zusammenfassend: Datenbasierte Projekte zu realisieren heisst weit mehr, als die notwendige Technologie zu beherrschen: wichtiger sind die solide Datenbasis, der klare Blick auf Wert und Wirkung und die bedingungslose Aufmerksamkeit auf Menschen und Kultur.
Unser Newsletter liefert dir brandaktuelle News, Insights aus unseren Studiengängen, inspirierende Tech- & Business-Events und spannende Job- und Projektausschreibungen, die die digitale Welt bewegen.