Big Data = Smart Data in Real Estate?
Dezember 16, 2017
Data Science hält Einzug in der Immobilienwelt!
Ein hochspannender Vormittag über Big Data und Real Estate mit Simon Caspar (Partner bei pom+), Lukas Stöcklin (Data Scientist bei pom+) und Stefan Hegglin (CEO, Gründer von Cybwell Media), wo wir uns u.a. auch wissenschaftlich mit der Titanic befassten…, aber alles der Reihe nach…
Aus dem Unterricht des CAS Digital Real Estate vom 25.11.2017 berichtet Jürg Kränzlin (lic. oec. HSG, CFO Credit Suisse Global Real Estate).

Die Immobilienwirtschaft verfügt über einen riesigen Immobilienbestand und beim Bau und Betrieb der Immobilien werden bei allen Prozessen enorme Datenmengen/Informationen produziert. Aber was macht die Immobilienwirtschaft mit diesen Daten? Heute noch relativ wenig!
S. Caspar und L. Stöcklin zeigen, wie es anders geht:
Dank heutiger IT-Technologie verschwinden die physischen Grenzen der Unternehmen, dies hat folgende Ursachen:
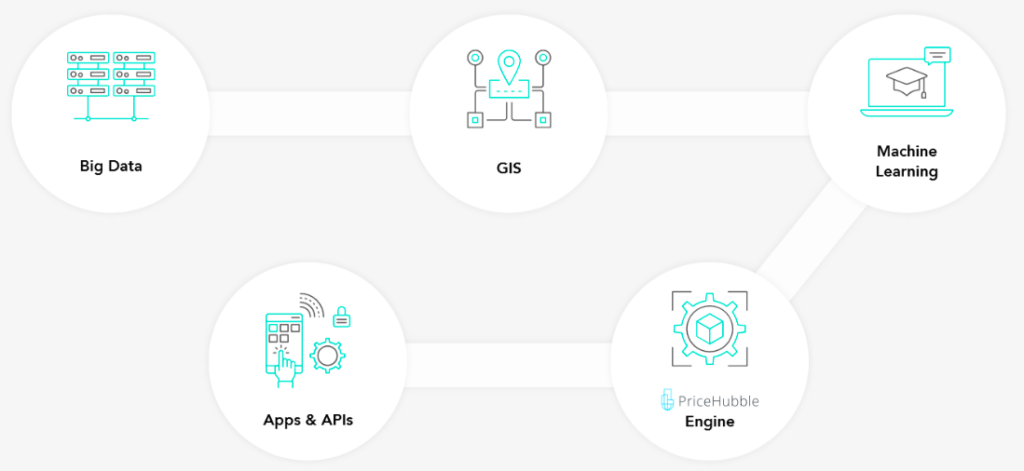
Quelle: Skript Caspar, S. 17 und Price Hubble
Hier setzt nun die Digitalisierung an: Die Immobilie als Datenpunkt wird mit dem Umfeld verknüpft und daraus werden ganz neue Anwendungsfelder möglich. Am Fallbeispiel von PriceHubble, einem der innovativsten Schweizer PropTech Startups, wurde dies anhand der Immobilienpreisbewertung gezeigt. PriceHubble verknüpft verschiedene Datenbestände und wertet sie mit machine learning aus:
Dazu meinte Simon Caspar: “Freud und Leid sind nahe beieinander”.
“Es sei Illusion zu glauben mit 2-3 Clicks in den grossen Datenwolken und dann habe ich das Resultat sei es gemacht! Nein es braucht viel Arbeit unter der Motorhaube”:
Im Unterricht konzentrierten wir uns dabei auf drei Schwerpunktthemen
“In 2 Minuten kannst du die Arbeit von 2 Wochen zerstören”
Was S. Caspar damit meint: “Die gute Visualisierung ist die Sahnehaube des Arbeitsergebnisses”. Dazu haben wir gute Tipps zu Werkzeugen und Anleitungen erhalten:
Als sehr gute Visualisierung haben wir das Beispiel “Student Dashboard” diskutiert:
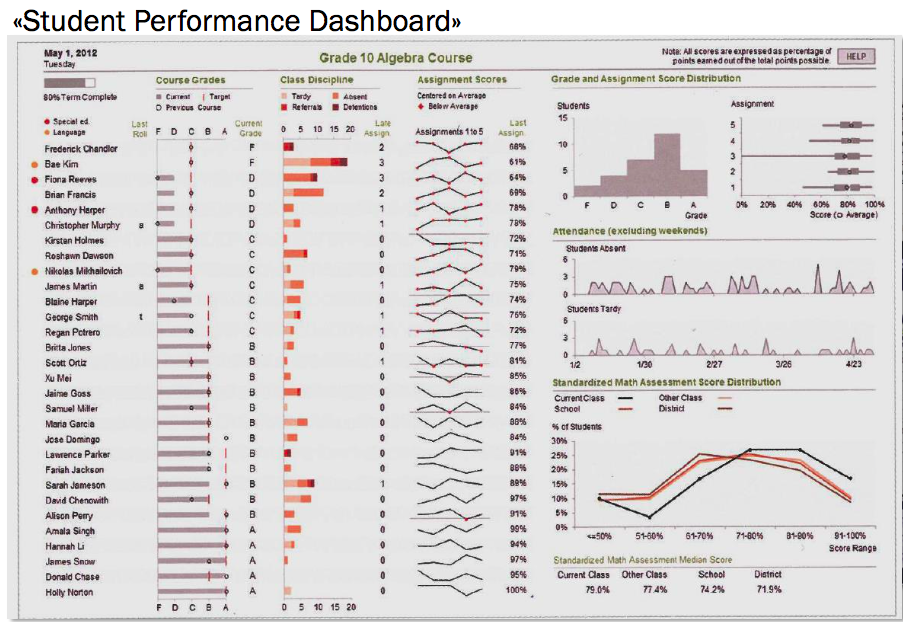 Quelle: Caspar, S. 31
Quelle: Caspar, S. 31
In der Interaktion Mensch-Maschine liegt der Erfolg!
Die Maschine ist dort dem Menschen überlegen, wo es darum geht, viel Rechenarbeit mit vordefinierten Modellen auszuführen.
Lukas Stöcklin, ein Quereinsteiger und Data Scientist, hat uns anhand der Titanic-Katastrophe in die Welt des Machine Learning eingeführt. Dabei wurde die Passagierliste der Titanic als “Trainingsdatensatz” verwendet. Das Ziel ist eine möglichst präzise Vorhersage zu erhalten, ob ein Passagier überlebt hat oder nicht. Dabei sind Geschlecht, Alter, Familie/Einzelreisender und soziale Herkunft (Kabinenklasse) die relevanten Merkmale. Mit einer entsprechenden Software und Rechenmodellen kann diese Prognose erstellt werden.
Das Vorgehen lässt sich wie folgen darstellen: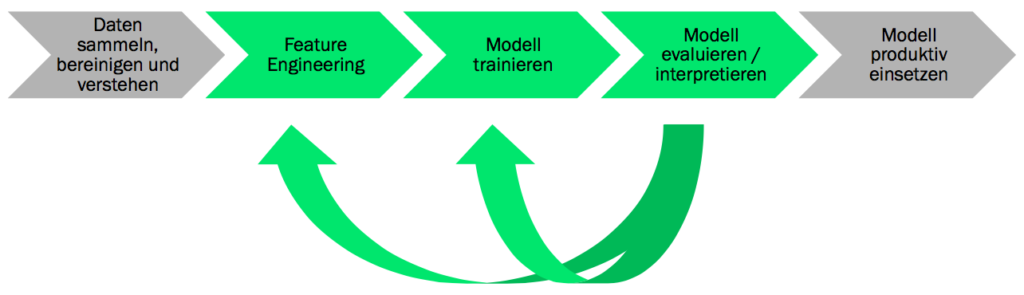
Die Trainingsdaten werden dabei in einen Testdatensatz umgebaut. Mittels Entscheidungsbaumverfahren und Random Forest Algorithmus wird dann das Modell bestimmt und trainiert. Die Ergebnisse waren erstaunlich gut und der Tatbeweis erbracht, dass auch die Maschine lernen kann.
Zum Schluss des Vormittages genossen wir einen spannenden Einblick in die Werkstatt für Webservices von Stefan Hegglin. Seine Spezialität ist die serviceorientierte IT-Architektur an der Schnittstelle zwischen Unternehmen und Kunde.
Mehr dazu im Video des Fraunhofer Instituts.
Zusammenfassend können die Vorteile der “Service orientierten Architektur” (SOA) wie folgt charakterisiert werden:
Mit SOA werden digitale Geschäftsmodelle möglich, die bis vor kurzem noch nicht realisierbar waren – einfach genial !
Als Beispiele haben wir folgende Anwendungsfälle kennengelernt:
Wir kamen aus dem Staunen nicht mehr heraus, wie viele wertvolle Informationen gratis im Internet beziehbar sind (Stichwort open data, government data) und was die Immobilienindustrie damit alles anfangen könnte.
Der Unterricht hätte noch länger dauern können … ein herzliches Dankeschön an die drei Top-Referenten Simon Caspar, Lukas Stöcklin und Stefan Hegglin!
weiterer Link: BigData
Unser Newsletter liefert dir brandaktuelle News, Insights aus unseren Studiengängen, inspirierende Tech- & Business-Events und spannende Job- und Projektausschreibungen, die die digitale Welt bewegen.